I wonder if it is possible to see the "data-id" element of tag elements in Python via Selenium as a class, id, or name.
What I mean is that the data I want is covered inside div element as underlined in picture, within the span and anchor elements with the same data-id="nba:schedule:main:team:link" attribute
.
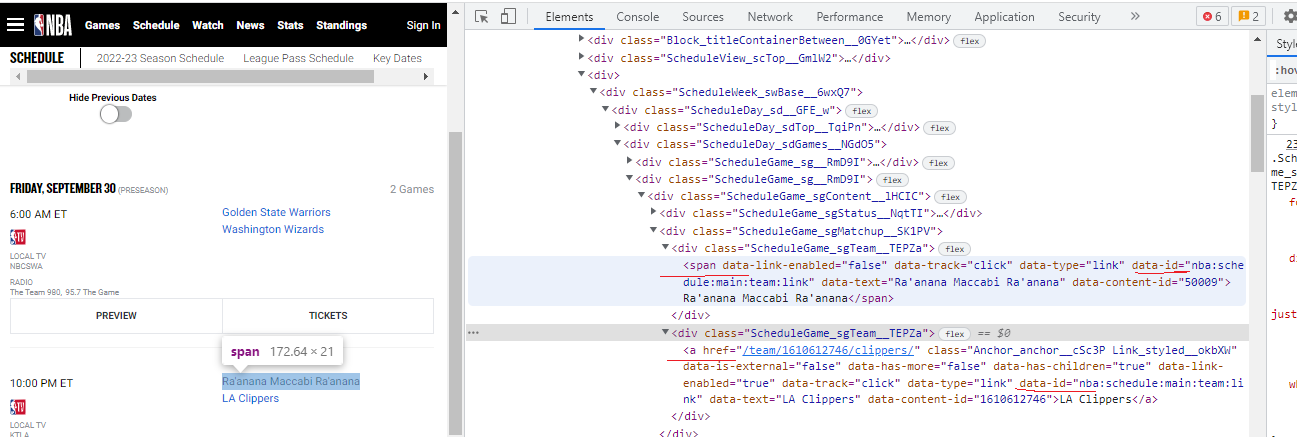
With code driver.find_elements(By.XPATH,"//a[@data-id='nba:schedule:main:team:link']") it sees only anchor elements. I wonder if there is a code to wrap up both data inside span and anchor elements only with single iteration like driver.find_elements(By.ID,"nba:schedule:main:team:link") or (By.XPATH,"//div//[@data-id='nba:schedule:main...']"
Whole code is below;
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from datetime import datetime
#import pandas as pd
driver = webdriver.Chrome(r"C:\Users\Admin\Downloads\chromedriver_win32 (1)\chromedriver.exe")
driver.get("https://www.nba.com/schedule?pd=false®ion=1")
driver.implicitly_wait(5)
element_to_click=driver.find_element(By.ID,"onetrust-accept-btn-handler") #.click()
element_to_click.click()
element_to_save=driver.find_element(By.XPATH,"//div/div/div/div/h4")
f=open(r'C:\pythonPro\t_bot\new_test.txt','r ')
f.write(element_to_save.text)
f.write("\n")
f.write(str(datetime.today()))
myList=[]
elements_to_save=driver.find_elements(By.XPATH,"//a[@data-id='nba:schedule:main:team:link']")
for element in elements_to_save:
f.write(element.text)
myList.append(element.text)
f.write(" \n ")
f.write(str(datetime.today()))
f.write(" ")
elements_to_save=driver.find_elements(By.ID,"nba:schedule:main:team:link")
for element in elements_to_save:
f.write(" ")
f.write(element.text)
f.write(" \n ")
f.write(str(datetime.today()))
f.close()
f=open(r'C:\pythonPro\t_bot\new_test.txt','r ')
print(f.read())
f.close()
time.sleep(3)
driver.get("https://www.nba.com/stats/teams/traditional")
print(myList)
driver.quit()
CodePudding user response:
Since both a and span elements there having the same id attribute value you can simple omit the tag name to match any tag element with the specified id attribute value, as following:
elements_to_save=driver.find_elements(By.XPATH,"//*[@data-id='nba:schedule:main:team:link']")