I'm attempting to modify a dataframe which contains a list of tuples within it's column values such that if a sequence of 'off' and 'on' is encountered for a sequence of tuples then they are removed from the dataframe.
Here is the dataframe prior to processing :
import pandas as pd
import numpy as np
array = np.array([[1, [('on',1),('off',1),('off',1),('on',1)]], [2,[('off',1),('on',1),('on',1),('off',1)]]])
index_values = ['first', 'second']
column_values = ['id', 'l']
df = pd.DataFrame(data = array,
index = index_values,
columns = column_values)
which renders :
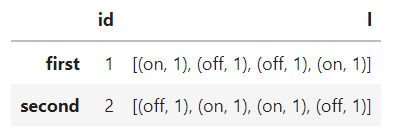
I'm attempting to produce this dataframe :
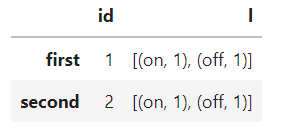
Here is my attempt :
updated_col = []
for d in df['l'] :
for index, value in enumerate(d) :
if len(value) == index :
break
elif value[index] == 'off' and value[index 1] == 'on' :
updated_col.append(value)
The variable updated_col is empty. Cana lambda be used to process over the column and remove values where a sequence of off and on are found ?
Edit :
Custom pairwise function :
this seems to do the trick :
import itertools
def pairwise(x) :
return list(itertools.combinations(x, 2))
CodePudding user response:
from itertools import pairwise
# Or (Depending on python version)
from more_itertools import pairwise
df.l = df.l.apply(lambda v: [x for x in pairwise(v)
if x == (('on', 1), ('off', 1))][0]).map(list)
Output:
id l
first 1 [(on, 1), (off, 1)]
second 2 [(on, 1), (off, 1)]
CodePudding user response:
If you want the unique values in each row, you can use set to update your dataframe
for i in range(df.shape[0]):
df['l'][i] = set(df['l'][i])
If you want to remove the duplicates in the sequence, you can use the itertools package like this:
from itertools import groupby
for i in range(df.shape[0]):
list_=[]
for k, c in groupby(df['l'][i]):
list_.append(k)
df['l'][i] = list_