I have a pandas dataframe with data from a university. I would like to store this in my Postgres DB using the to_sql method, but to do so I would have to flatten it into 1 row.
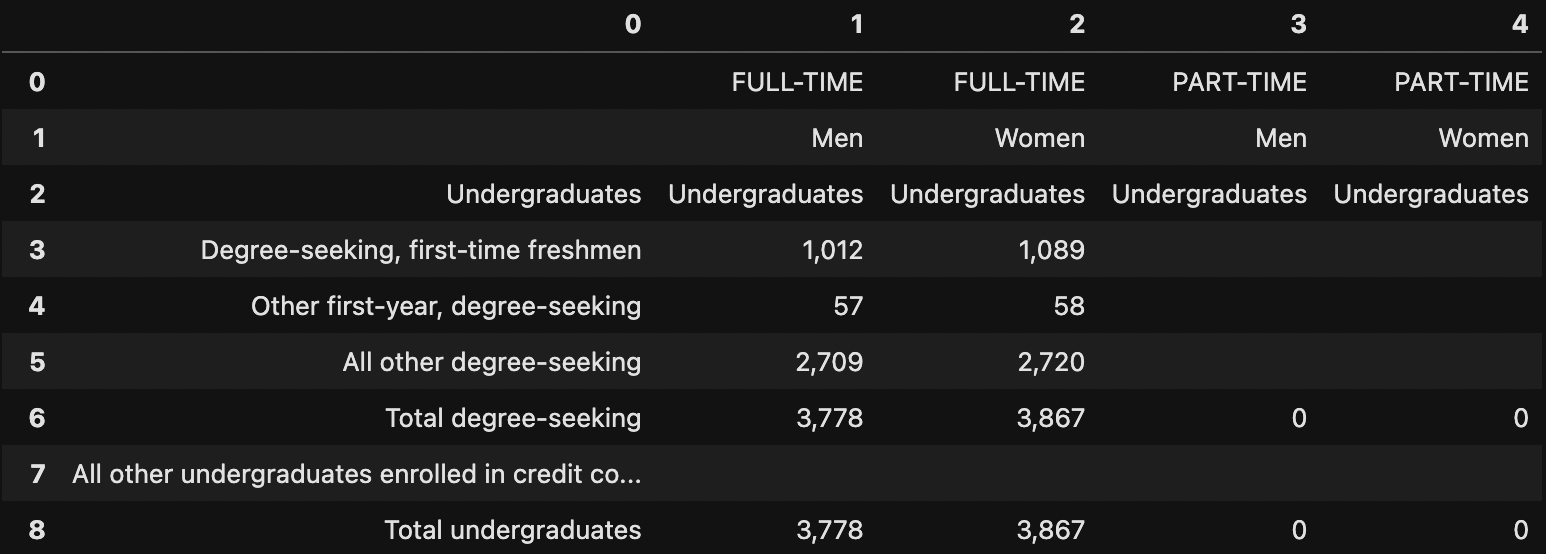
I would like the DF above to look like this (both pictures are the same row but broken up to fit on the screen):
1)

2)

How can I achieve this?
Data:
CSV of original dataframe
,0,1,2,3,4
0,,FULL-TIME,FULL-TIME,PART-TIME,PART-TIME
1,,Men,Women,Men,Women
2,Undergraduates,Undergraduates,Undergraduates,Undergraduates,Undergraduates
3,"Degree-seeking, first-time freshmen","1,012","1,089",,
4,"Other first-year, degree-seeking",57,58,,
5,All other degree-seeking,"2,709","2,720",,
6,Total degree-seeking,"3,778","3,867",0,0
7,All other undergraduates enrolled in credit courses,,,,
8,Total undergraduates,"3,778","3,867",0,0
Dataframe construction for desired output:
pd.DataFrame({
'FULL-TIME Men Undergraduates Degree-seeking, first-time freshmen': [1012],
'FULL-TIME Women Undergraduates Degree-seeking, first-time freshmen': [1089],
'PART-TIME Men Undergraduates Degree-seeking, first-time freshmen': [None],
'PART-TIME Women Undergraduates Degree-seeking, first-time freshmen': [None],
'FULL-TIME Men Undergraduates Other first-year, degree-seeking': [57],
'FULL-TIME Women Undergraduates Other first-year, degree-seeking': [58],
'PART-TIME Men Undergraduates Other first-year, degree-seeking': [None],
'PART-TIME Women Undergraduates Other first-year, degree-seeking': [None],
'FULL-TIME Men Undergraduates All other degree-seeking': [2709],
'FULL-TIME Women Undergraduates All other degree-seeking': [2720],
'PART-TIME Men Undergraduates All other degree-seeking': [None],
'PART-TIME Women Undergraduates All other degree-seeking': [None],
'FULL-TIME Men Undergraduates Total degree-seeking': [3778],
'FULL-TIME Women Undergraduates Total degree-seeking': [3867],
'PART-TIME Men Undergraduates Total degree-seeking': [None],
'PART-TIME Women Undergraduates Total degree-seeking': [None],
'FULL-TIME Men Undergraduates Total undergraduates': [3778],
'FULL-TIME Women Undergraduates Total undergraduates': [3867],
'PART-TIME Men Undergraduates Total undergraduates': [None],
'PART-TIME Women Undergraduates Total undergraduates': [None],
})
EDIT 1:
Each cell in the original becomes a cell in the single row produced. The first 3 rows in the CSV actually make a MultiIndex [(full-time, men, undergraduates), (full-time, women, undergraduates), (part-time, men, undergraduates), (part-time, women, undergraduates)]. The first Column (0) is also an index. I'm essentially combining the indexes and flattening all values into a wide format.
Here is an image of the original table, I am extracting the data from PDF images.
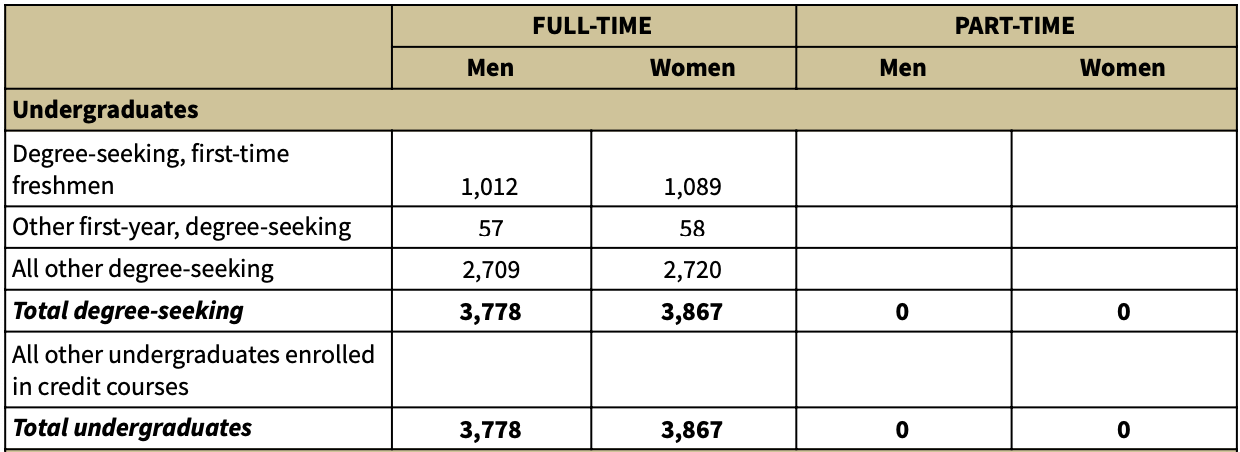
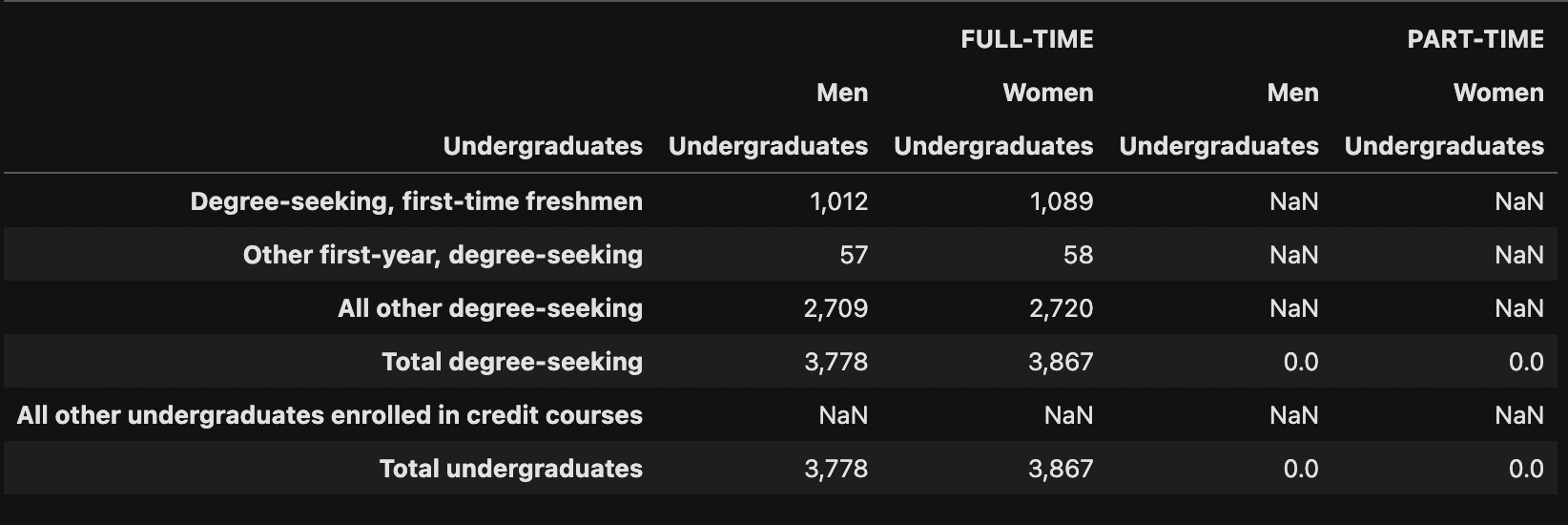
To reproduce this exactly:
pd.read_csv('path/to/example.csv', header=[1,2,3], index_col=[1]).drop([('0','1','2')], axis=1)
Which then produces:
CodePudding user response:
Your CSV is pretty scuffed, and really contains multiple tables, so there's some work that needs to be done to clean it up.
# Your first row is irrelevant,
# the relevant index is column 1,
# and you have two header rows.
df = pd.read_csv('text.csv', skiprows=1, index_col=1, header=[0,1])
# This leaves us a useless '0' column:
df = df.drop('0', axis=1)
# You have two tables here, so we'll break them apart.
dfs = (('Undergraduates', df.loc['Undergraduates':'Graduate'].drop('Graduate')),
('Graduate', df.loc['Graduate':]))
def fix_subcolumn(title, d):
# Modify their columns:
d.columns = pd.MultiIndex.from_tuples([(*x, title) for x in d.columns])
# Drop useless rows:
d = d.drop(title)
# Now, if we transpose and melt your dataframe, we're closer to what you want.
# This is similar to unstacking, but doesn't lose your ordering.
d = d.T.melt(ignore_index=False)
return d
# Apply this function to both:
dfs = [fix_subcolumn(t, d) for t, d in dfs]
# Concat them together:
df = pd.concat(dfs)
# Add 'variable' col to your index
df = df.set_index('variable', append=True)
# Join your index together. Make this your index.
df.index = [' '.join(x) for x in df.index]
# We can do some quick cleanup if desired:
df['value'] = pd.to_numeric(df['value'].str.replace(',', '')).astype('Int32')
# Transpose
df = df.T
print(df)
Output... which is a horrible format for a DataFrame:
FULL-TIME Men Undergraduates Degree-seeking, first-time freshmen ... PART-TIME Women Graduate Total all students
value 1012 ... 343
[1 rows x 44 columns]
Given either subframe:
df_u = df.loc['Undergraduates':'Graduate'].drop(['Undergraduates','Graduate'])
# add a new column:
df_u['col'] = 'Undergraduates'
# Append it to your index, and melt, reset_index:
df_u = (df_u.set_index('col', append=True)
.melt(ignore_index=False)
.reset_index())
# I'd drop the total rows:
df_u = df_u[~df_u['level_0'].str.contains('Total')]
# Do some re-naming:
df_u = df_u.rename(columns={'variable_0':'full_time', 'variable_1':'gender'})
df_u.level_0 = df_u.level_0.str.lower()
rename = {
'degree-seeking, first-time freshmen': '1,first-year freshmen',
'other first-year, degree-seeking': '1,first-year other',
'all other degree-seeking': '1,other',
'all other undergraduates enrolled in credit courses': '0,other'
}
df_u.level_0 = df_u.level_0.replace(rename)
# Split up this information:
df_u[['degree_seeking', 'level_0']] = df_u.level_0.str.split(',', expand=True)
# Dtype stuff
df_u.degree_seeking = df_u.degree_seeking.astype(int).astype(bool)
df_u.full_time = df_u.full_time.replace('PART-TIME', 0).astype(bool)
df_u.value = pd.to_numeric(df_u.value.str.replace(',', '')).astype('Int32')
print(df_u)
Output, Give relevant column names and datatypes... and this should go in a database just fine:
level_0 col full_time gender value degree_seeking
0 first-year freshmen Undergraduates True Men 1012 True
1 first-year other Undergraduates True Men 57 True
2 other Undergraduates True Men 2709 True
4 other Undergraduates True Men <NA> False
6 first-year freshmen Undergraduates True Women 1089 True
7 first-year other Undergraduates True Women 58 True
8 other Undergraduates True Women 2720 True
10 other Undergraduates True Women <NA> False
12 first-year freshmen Undergraduates False Men <NA> True
13 first-year other Undergraduates False Men <NA> True
14 other Undergraduates False Men <NA> True
16 other Undergraduates False Men <NA> False
18 first-year freshmen Undergraduates False Women <NA> True
19 first-year other Undergraduates False Women <NA> True
20 other Undergraduates False Women <NA> True
22 other Undergraduates False Women <NA> False
SELECT SUM(value)
FROM t
WHERE gender = 'Women'
AND full_time
AND col = 'Undergraduates'
AND degree_seeking
-- Intuitively Returns:
-- 3867