I have a column in dataframe which has string values like
"Hardware part not present"
"Software part not present"
null
null
I want to split wrt " " and take only first 2 strings to new column and if it is null then even new column value should be null as well. how to achieve this?
result needed
column New column
Hardware part not present Hardware part
Software part not present Software part
null null
null null
how to achieve this using pyspark or python
CodePudding user response:
Code:
df['New col'] = df.fillna('').apply(lambda x: ' '.join(x.col.split(' ')[:2]), axis=1)
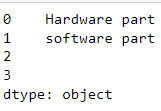
CodePudding user response:
Pandas has a built in split method. Here you can define the total number of splits to limit how deep it goes into the string.
df[“existingcol”].str.split(n=2, expand=true)
This will give you 3 columns. Then just concat the first 2, and then drop any unnecessary cols.
Doco for reference: https://pandas.pydata.org/docs/reference/api/pandas.Series.str.split.html
It defaults to splitting on white space, but if you think there’ll be a comma or something in there, you can always split on a regex pattern.
CodePudding user response:
In pyspark, you can achieve this using concat_ws, slice and split functions.
data_sdf. \
withColumn('text_frst2',
func.when(func.col('text').isNotNull(),
func.concat_ws(' ', func.slice(func.split('text', ' '), 1, 2))
)
). \
show(truncate=False)
# ---------------------------- -------------
# |text |text_frst2 |
# ---------------------------- -------------
# |software part is not present|software part|
# |hardware part is not present|hardware part|
# |null |null |
# |foo bar baz |foo bar |
# ---------------------------- -------------
splitwill split the text based on the provided delimiter (in this case" ")slicewill retain N number of elements starting from Kth position (in this caseN=2andK=1)concat_wsconcatenates the array elements delimited by the provided delimiter (in this case" ")- I used a
when()to only use the operations on non-null values as this generates a space/blank value for null