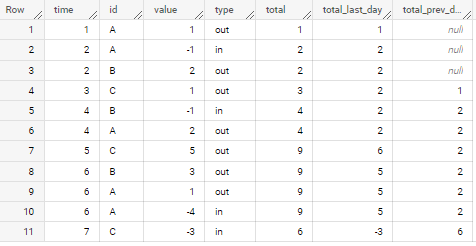
I'm running out of memory with my query on Google BigQuery. I have to calculate multiple window functions like running sums over multiple different time frames. My data mainly consists of an id (string), a value (number), a type ('in' or 'out', could be converted to bool is needed) and a timestamp.
I read that there is no way to increase memory per slot, so the only way to be able to execute the query is to cut it into smaller pieces that can be sent to different slots. A way to do this is to use GROUP BY or OVER (PARTITION BY ...) but I have no idea how I could rewrite my query to make use of it.
I have some calculations that need to use PARTITION BY but for others, I want to calculate the total overall, for example:
Imagine a have a large table (> 1 billion rows) where I want to calculate a rolling sum over all values for different time frames, independent of id.
WITH data AS (
SELECT *
FROM UNNEST([
STRUCT
('A' as id,1 as value, 'out' as type, 1 as time),
('A', -1, 'in', 2),
('B', 2, 'out', 2),
('C', 1, 'out', 3),
('B', -1, 'in', 4),
('A', 2, 'out', 4),
('C', 5, 'out', 5),
('B', 3, 'out', 6),
('A', 1, 'out', 6),
('A', -4, 'in', 6),
('C', -3, 'in', 7)
])
)
SELECT
id
, value
, type
, time
, SUM(value) OVER (ORDER BY time RANGE UNBOUNDED PRECEDING) as total
, SUM(value) OVER (ORDER BY time RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) as total_last_day
, SUM(value) OVER (ORDER BY time RANGE BETWEEN 3 PRECEDING AND 2 PRECEDING) as total_prev_day
FROM data
How could I split this query to make use of PARTITION BY or GROUP BY in order to fit within the memory limits?
CodePudding user response:
Window functions with specially order by partition by etc are in general very heavy and using it on big data can take long.
It looks like your expected result is keying of of your id in your sample query.
There are a few things you can check:
see if your source data can be "cluster by" id so processing will be faster to start with.
If that does not work, then see adding following style of filters will work or not:
select ...
where mod(farm_fingerprint(id), 5) = 0
store it in a table and keep appending next mods (=1 to 4) to that table. "%5=0" mod is given as a sample, you have to experiment with it knowing your source data. Here using mod will split your source data into 5 smaller buckets to work with so you have to append it all later. That way amount of data needed for BQ internal memory will be less and it might process results in its limits.
If any of above ideas work, you can all do that in a sql script so you can create temp tables and work with those.
CodePudding user response:
Try below approach - I think it has good chances to resolve your issue
SELECT *
FROM data
JOIN (
SELECT time
, SUM(time_value) OVER (ORDER BY time RANGE UNBOUNDED PRECEDING) as total
, SUM(time_value) OVER (ORDER BY time RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) as total_last_day
, SUM(time_value) OVER (ORDER BY time RANGE BETWEEN 3 PRECEDING AND 2 PRECEDING) as total_prev_day
FROM (
SELECT time, SUM(value) time_value
FROM data
GROUP BY time
)
)
USING (time)
if applied to sample data in your question - output is