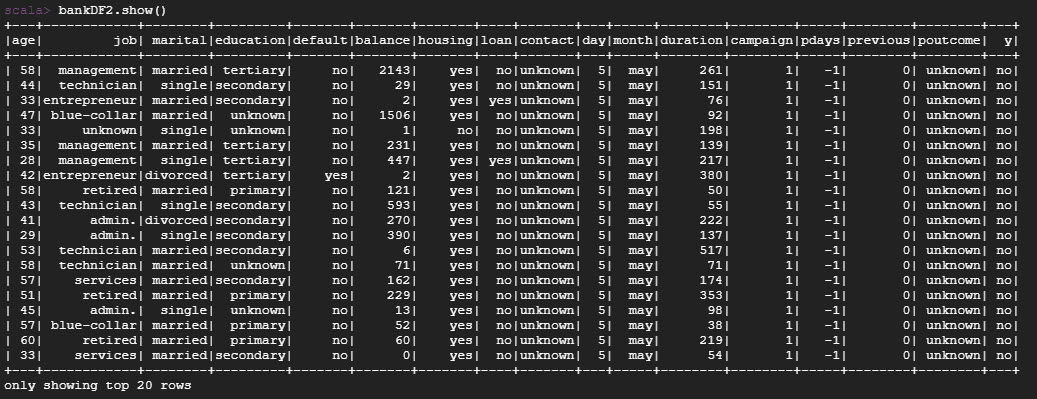
I'm working on a small project using Spark data frames with Scala. I've managed to clean some data from a .csv file, but the end result (output) includes a single column where the "age" and "job" data are combined. Please see the attached screenshot.
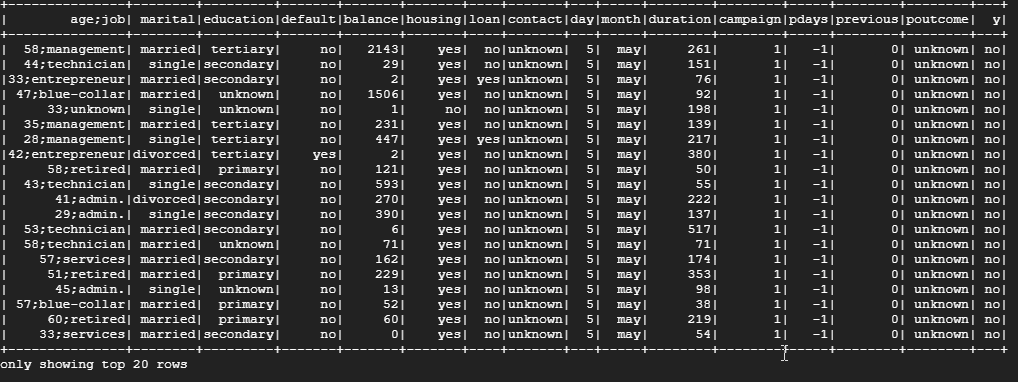
I'm looking to split the "age;job" column into two separate columns called "age" and "job", drop the "age;job" column, and keep the rest of the data in tact.
I've been working on this one for quite awhile, but I'm presently stuck. Any and all feedback is most welcomed and appreciated.
Note: I'm using Scala on Spark Shell, not an IDE like IntelliJ. Just a heads up, as I'll need to accomplish this using the Spark Shell CLI.
CodePudding user response:
You can use split:
import org.apache.spark.sql.functions.{col, split}
val column = split(col("field"), ";")
df.withColumn("left", column(0)).withColumn("right", column(1)).show()
and as result:
----------- ----- -----
| field| left|right|
----------- ----- -----
|data1;data2|data1|data2|
----------- ----- -----
CodePudding user response:
I figured out the issue. I simply just fixed the raw .csv file.
Below I have a snippet of the .csv file. Notice the "age" header at the top left hand corner was missing double quotation marks.

All I did was simply add those double quotes and that fixed the problem. Below is my new output.