I have a table that has the following columns: Item, Date, Status Description, and Stock Status. It contains historical data for the stocking status of items.
Below is a brief sample of the input in table form.
| Item | Date | Status Description | Stock Status |
|---|---|---|---|
| ABC123 | 2020-10-02 | Listed Out of Stock (ABC123) | Out of Stock |
| ABC123 | 2020-10-15 | In Stock (ABC123) | In Stock |
| ABC123 | 2021-05-04 | Listed Out of Stock (ABC123) | Out of Stock |
| ABC123 | 2021-07-15 | Listed Out of Stock (ABC123) | Out of Stock |
| ABC123 | 2021-07-27 | Listed Out of Stock (ABC123) | Out of Stock |
| ABC123 | 2021-08-09 | Listed Out of Stock (ABC123) | Out of Stock |
| ABC123 | 2021-10-19 | In Stock (ABC123) | In Stock |
| ... | ... | ... | ... |
And here is a script to create the test input data into a temp table.
DROP TABLE #OOS_History;
CREATE TABLE #OOS_History
(
[Item] NVARCHAR(100),
[Date] DATETIME2,
[Status Description] NVARCHAR(100),
[Stock Status] NVARCHAR(25)
);
INSERT INTO #OOS_History ( [Item], [Date], [Status Description], [Stock Status] )
VALUES
('ABC123', '10/2/2020 13:53', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '10/15/2020 9:20', 'In Stock (ABC123)', 'In Stock'),
('ABC123', '5/4/2021 8:22', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '7/15/2021 13:47', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '7/27/2021 8:04', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '8/9/2021 13:12', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '10/19/2021 8:04', 'In Stock (ABC123)', 'In Stock'),
('ABC123', '10/28/2021 11:52', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '10/29/2021 9:24', 'In Stock (ABC123)', 'In Stock'),
('ABC123', '12/6/2021 7:00', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '12/6/2021 7:02', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '12/15/2021 10:47', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '2/21/2022 14:25', 'In Stock (ABC123)', 'In Stock'),
('ABC123', '4/7/2022 8:36', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '4/13/2022 7:39', 'In Stock (ABC123)', 'In Stock'),
('ABC123', '4/19/2022 13:06', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '4/22/2022 14:07', 'In Stock (ABC123)', 'In Stock'),
('ABC123', '4/28/2022 11:30', 'Listed Out of Stock (ABC123)', 'Out of Stock'),
('ABC123', '5/21/2022 6:25', 'In Stock (ABC123)', 'In Stock'),
('ABC123', '7/12/2022 14:10', 'Listed Out of Stock (ABC123)', 'Out of Stock');
My goal is to create a new table that has the following 3 columns: Item, Start Date, and End Date. Each row will represent an interval that an item is out of stock.
Below is the desired output which should list the intervals (start and end date) that an item was out of stock.
| Item | Start Date | End Date |
|---|---|---|
| ABC123 | 2020-10-02 | 2020-10-15 |
| ABC123 | 2021-05-04 | 2021-10-19 |
| ABC123 | 2021-10-28 | 2021-10-29 |
| ABC123 | 2021-12-06 | 2021-12-15 |
| ABC123 | 2022-04-07 | 2022-04-13 |
| ABC123 | 2022-04-19 | 2022-04-22 |
| ABC123 | 2022-04-28 | 2022-05-21 |
| ABC123 | 2022-07-12 | NULL |
I believe I can do this by finding the groups that each row belongs in. In this case there should be 8 groups (rows 1-2), (rows 3-7), (rows 8-9), (rows 10-13), (rows 14-15), (rows 16-17), (rows 18-19), and (row 20). Then I can take the first row from each group as the starting date and the last row from each group as the ending date.
I've done some preliminary research and this appears to be an islands and gaps problem. I've found an answer on stackoverflow that looks like a good starting point but I'm stuck on how to apply it to my problem.
I'm copying the SQL query structure from the answer on this stackoverflow post (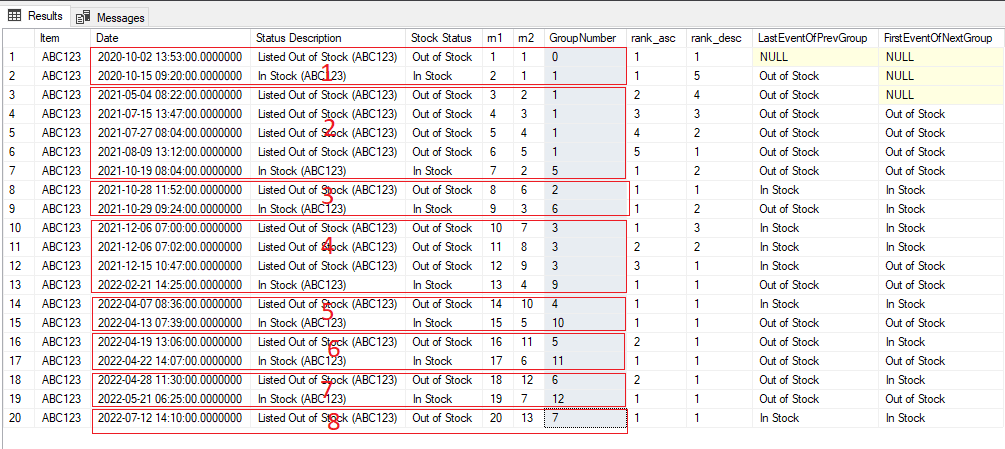
CodePudding user response:
Here's a more intuitive approach, in my opinion:
WITH
OOS_History_With_Status_Change_Flag AS
(
SELECT
*,
CASE
WHEN LAG([Stock Status], 1, 1) OVER (ORDER BY [Date]) <> [Stock Status]
THEN 1 -- i.e. the status changed on this date
END AS [Status Change]
FROM
#OOS_History
),
OOS_History_Only_Status_Changes AS
(
SELECT
*,
CAST([Date] AS DATE) AS [Start Date],
CAST(LEAD([Date], 1) OVER (ORDER BY [Date]) AS DATE) AS [End Date]
FROM
OOS_History_With_Status_Change_Flag
WHERE
[Status Change] = 1
)
SELECT
[Item],
[Start Date],
[End Date]
FROM
OOS_History_Only_Status_Changes
WHERE
[Stock Status] = 'Out of Stock'
ORDER BY
[Start Date]
;
In essence, the only rows you care about from your initial dataset are ones that represent a status change (i.e. rows with a lagging row, when ordered by date, of differing status). The first CTE creates this flag column using the LAG() function; the second CTE uses this flag as a filter and defines the Start Date and End Date columns.
And just like that, you're done! Select rows where the status is out-of-stock, and you're golden.