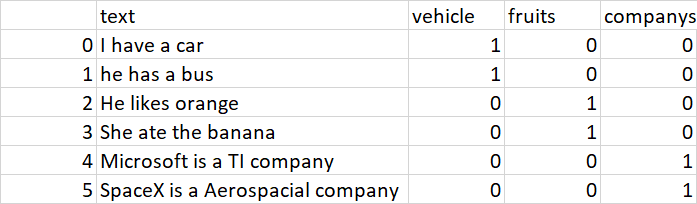
I have 3 dataframes and they have only one column: text
df1
text
I have a car
he has a bus
df1.shape = (10000,1)
df2
text
He likes orange
She ate the banana
df2.shape = (10000,1)
df3
text
Microsoft is a TI company
SpaceX is a Aerospacial company
df3.shape = (10000,1)
I want to create another dataframe, merging df1, df2 and df3 to get this as output:
text vehicle fruits companys
I have a car 1 0 0
he has a bus 1 0 0
He likes orange 0 1 0
She ate the banana 0 1 0
Microsoft is a TI company 0 0 1
SpaceX is a Aerospacial company 0 0 1
output.shape = (30000,4)
How can I do this?
CodePudding user response:
There are various ways to achieve what OP desired.
IMO what OP wants is to check if there are vehicles, fruits or companies the the strings.
In order to do that, one will need to first define what is a vehicle, a fruit or a company. For that, one can create a list for each (the lists can be improved)
vehicles = ["car", "bus", "motorcycle", "airplane", "train", "boat", "ship", "helicopter", "submarine", "rocket", "spaceship"]
fruits = ["banana", "apple", "orange", "grape", "strawberry", "watermelon", "cherry", "peach", "pear", "mango", "pineapple"]
companies = ["Microsoft", "Apple", "Google", "Amazon", "Facebook", "Tesla", "SpaceX", "Boeing", "Airbus", "Lockheed", "NASA"]
Now, with the lists, one can merge the dataframes with pandas.concat
df_merge = pd.concat([df1, df2, df3], axis=0, ignore_index=True)
[Out]:
text
0 I have a car
1 he has a bus
2 He likes orange
3 She ate the banana
4 Microsoft is a TI company
5 SpaceX is a Aerospacial company
And now, with the merged dataframe, one can check if the values in the lists above are present in the rows.
We start with the vehicles
df_merge['vehicles'] = df_merge['text'].apply(lambda x: sum([x.count(i) for i in vehicles]))
[Out]:
text vehicles
0 I have a car 1
1 he has a bus 1
2 He likes orange 0
3 She ate the banana 0
4 Microsoft is a TI company 0
5 SpaceX is a Aerospacial company 0
Now we move to fruits
df_merge['fruits'] = df_merge['text'].apply(lambda x: sum([x.count(i) for i in fruits]))
[Out]:
text vehicles fruits
0 I have a car 1 0
1 he has a bus 1 0
2 He likes orange 0 1
3 She ate the banana 0 1
4 Microsoft is a TI company 0 0
5 SpaceX is a Aerospacial company 0 0
Finally, we do it for companies
df_merge['companies'] = df_merge['text'].apply(lambda x: sum([x.count(i) for i in companies]))# Print the result
[Out]:
text vehicles fruits companies
0 I have a car 1 0 0
1 he has a bus 1 0 0
2 He likes orange 0 1 0
3 She ate the banana 0 1 0
4 Microsoft is a TI company 0 0 1
5 SpaceX is a Aerospacial company 0 0 1
Notes:
Even though out of scope for this example, this approach has, at least, one limitation. More specifically, if a string has an orange vehicle, for example
She has an orange bus, it will detect both a vehicle and a fruit. If one wants to accommodate that, one will have to do it from here.Apart from the point above, there are more that can happen, however, to consider all, one would need to have access to the full dataframe.
CodePudding user response:
Try this
df1 = pd.DataFrame({"text":["I have a car","he has a bus"]})
df1["vehicle"] = 1
df2 = pd.DataFrame({"text":["He likes orange","She ate the banana"]})
df2["fruits"] = 1
df3 = pd.DataFrame({"text":["Microsoft is a TI company","SpaceX is a Aerospacial company"]})
df3["companys"] = 1
df4 = pd.concat([df1,df2,df3])
df4.fillna(0,inplace=True)
df4.index = range(0,df4.shape[0])
Output of df4