My pandas dataframe has a column(series) with comma separated string values looking like this:
col_1,col_2,col_3
abc,123,49
bcd,234,"39,48"
I want to convert this col_3 into a list of integers. I tried
df["col_3"]=[[i] for i in df["col_3"]]
But I end up getting this result
col_1,col_2,col_3
abc,123,['49']
bcd,234,"['39,48']"
The desired output is
col_1,col_2,col_3
abc,123,[49]
bcd,234,[39,48]
I also want it to be fast because I would be using this for batches of 100k rows. Can some one suggest a solution . TIA
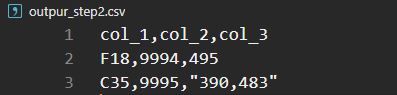
col_1 col_2 col_3
0 F18 9994 495
1 C35 9995 390,483
3 F60 9998 497,468
CodePudding user response:
You can use pandas.Series.str.split with a list comprehension :
df['col_3'] = [[int(e) for e in x.split(",")] for x in df['col_3']]
# Output :
print(df)
col_1 col_2 col_3
0 abc 123 [49]
1 bcd 234 [39, 48]
print(type(df.loc[0, 'col_3'][0]))
int
# Edit :
If you need to save your df to a .csv, there will be always double quotes between all the lists of integers (with a length > 1) since the elements of a list is separated by a comma and the default separator of pandas.DataFrame.to_csv is the comma as well. Double quotes are there to escape the commas inside these lists. So, to get rid of the double quotes, you have to choose another separator like the tab for example :
df.to_csv(r'path_to_your_new_csv', sep='\t')
CodePudding user response:
I am piggybacking on abokey's answer because they are already on the right track. Please let me know my dummy dataframe is not in your required format.
import pandas as pd
df = pd.DataFrame({"col1":["F18", "C35"], "col2":[9994, 9995], "col3":[43, '"39,48"']})
Using str.split would seperate your string elements into a list of substrings, based on your delimiter. he benefir of the appraoch is the whole string is put in a list, when the delimiter cannot be found as in df.loc[0, "col3"]. Afterwards, we apply list comprehension to change dtype of each element from str to int since it is your preferred format.
df["col3"] = df["col3"].apply(lambda x: [int(i) for i in str(x).strip('"').split(",")])
Edit: I updated the values based on your screenshot. use tqdm to see the progress when you are running on 100k rows.
!pip install tqdm
from tqdm import tqdm
tqdm.pandas()
df["col3"] = df["col3"].progress_apply(lambda x: [int(i) for i in str(x).strip('"').split(",")])
I can recommend pandarallel to parallel process through rows but it does not always work in my experience.
!pip install pandarallel
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True, nb_workers=4)
df["col3"] = df["col3"].parallel_apply(lambda x: [int(i) for i in str(x).strip('"').split(",")])