I am writing a Spark SQL, like this
select
colA, # possible values "A" and "B"
colB,
count(*) / (select count(*) from table_3 where colA = "A") as colC_A,
count(*) / (select count(*) from table_3 where colA = "B") as colC_B,
from
table_1 a
join
table_2 b on
a.colA = b.colA and
a.colB = b.colB
group by
colA, colB
I want to do something like this, to avoid unnecessary extra columns
select
colA, # line x
colB,
count(*) / (select count(*) from table_3 where colA = a.colA) as colC # line y
from
table_1 a
join
table_2 b on
a.colA = b.colA and
a.colB = b.colB
group by
colA, colB
Whatever the value is in line x, I want to use that in the where clause of line y.
Is it somehow possible? This strictly needs to be a single query.
CodePudding user response:
Sample Data - employee
#
# 1 - Create sample employee data
#
# array of tuples - data
dat1 = [
(1,"Smith",-1,"2018",10,"M",300000),
(2,"Rose",1,"2010",20,"M",225000),
(3,"Williams",2,"2010",30,"M",100000),
(4,"Brown",2,"2010",30,"F",125000),
(5,"Jones",1,"2010",50,"F",250000),
(6,"Headrick",5,"2010",50,"F",175000),
(7,"Murphy",5,"2010",50,"F",150000)
]
# array of names - columns
col1 = ["emp_id","name","superior_emp_id","branch_id","dept_id","gender","salary"]
# make data frame
df1 = spark.createDataFrame(data=dat1, schema=col1)
# create table
df1.createOrReplaceTempView("employees")
Sample Data - Departments
#
# 2 - Create sample department data
#
# array of tuples - data
dat1 = [
("Finance",10,"2018"),
("Marketing",20,"2010"),
("Marketing",20,"2018"),
("Sales",30,"2005"),
("Sales",30,"2010"),
("IT",50,"2010")
]
# array of names - columns
col1 = ["dept_name","dept_id","branch_id"]
# make data frame
df1 = spark.createDataFrame(data=dat1, schema=col1)
# create table
df1.createOrReplaceTempView("departments")
Sample Data - Anonymous Donations by Department
#
# 3 - Create sample donations
#
# array of tuples - data
dat1 = [
(10,"100"),
(20,"75"),
(20,"75"),
(30,"150"),
(30,"50"),
(30,"150"),
(50,"75"),
(50,"150"),
(50,"150"),
(50,"75")
]
# array of names - columns
col1 = ["dept_id","donation_usd"]
# make data frame
df1 = spark.createDataFrame(data=dat1, schema=col1)
# create table
df1.createOrReplaceTempView("donations")
This query fails!

%sql
select
e.dept_id,
e.branch_id,
count(*) as employees,
(select count(*) from donations as m where m.dept_id = e.dept_id) as total_donations
from
employees as e
left join
departments as d
on
e.dept_id = d.dept_id and e.branch_id = d.branch_id
group by
e.dept_id,
e.branch_id
Replace the correlated sub query with a CTE and join on the department id.
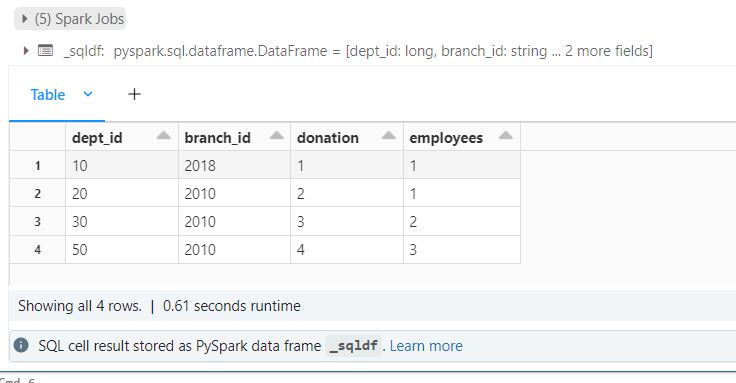
%sql
with cte_data as
(
select dept_id, count(*) as donation_cnt from donations group by dept_id
)
select
e.dept_id,
e.branch_id,
first(c.donation_cnt) as donation,
count(*) as employees
from
employees as e
left join
departments as d
on
e.dept_id = d.dept_id and e.branch_id = d.branch_id
left join
cte_data as c on c.dept_id = e.dept_id
group by
e.dept_id,
e.branch_id
This query works!
CodePudding user response:
From the tags, I assume you use PySpark. You could have a variable with the name of the column as string. Then when creating the query, you could use an f-string adding this column name inside.
Python code:
c = 'colN'
query = f"""
select
{c},
colB,
count(*) / (select count(*) from table_3 where colA = a.{c}) as colC
from
table_1 a
join
table_2 b on
a.colA = b.colA and
a.colB = b.colB
group by
colA, colB
"""
print(query)
which prints
select
colN,
colB,
count(*) / (select count(*) from table_3 where colA = a.colN) as colC
from
table_1 a
join
table_2 b on
a.colA = b.colA and
a.colB = b.colB
group by
colA, colB
You can use it as usual in PySpark:
spark.sql(query)