I am trying to scrape some film critic review information from Rotten Tomatoes. I've managed to access the json API files and am able to pull the data I need from the first page of reviews using the code below. The problem is I can't get my code to iterate through a list of url tokens I've created that should allow my scraper to move on to other pages of the data. The current code pulls data from the first page 11 times (resulting in 550 entries for the same 50 reviews) It always seems like the most simple things trip me up with this stuff. Can anyone tell me what I'm doing wrong?
import requests
import pandas as pd
baseurl = "https://www.rottentomatoes.com/napi/critics/"
endpoint = "alison-willmore/movies?"
tokens = [" ", "after=MA==", "after=MQ==", "after=Mg==", "after=Mw==", "after=NA==",
"after=NQ==", "after=Ng==", "after=Nw==", "after=OA==", "after=OQ$3D="]
def tokenize(t):
for y in t:
return y
def main_request(baseurl, endpoint, x):
r = requests.get(baseurl endpoint f'{x}')
return r.json()
reviews = []
def parse_json(response):
for item in response["reviews"]:
review_info = {
'film_title': item["mediaTitle"],
'release_year': item["mediaInfo"],
'full_review_url': item["url"],
'review_date': item["date"],
'rt_quote': item["quote"],
'film_info_link': item["mediaUrl"]}
reviews.append(review_info)
for t in tokens:
data = main_request(baseurl, endpoint, tokenize(t))
parse_json(data)
print(len(reviews))
d_frame = pd.DataFrame(reviews)
print(d_frame.head(), d_frame.tail())
CodePudding user response:
The issue is with your main_request method. Using a print statement or debugger is useful in this situation.
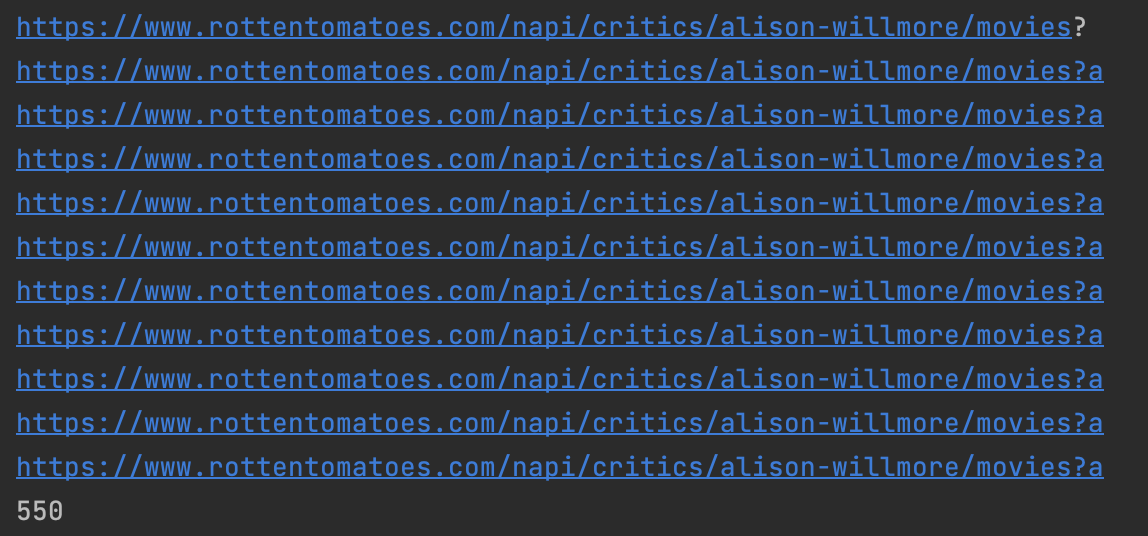
This shows that your code is requesting the same url multiple times. Thus your concatenation isn't working or is wrong. Next step is to figure out why a is the only thing in the URL.
def tokenize(t):
for y in t:
return y
This is your culprit. It is iterating through a string array and returning the first character in the array, which is the letter a (from after=SOMETHING) if that doesn't make sense, I would give this a read. What are you trying to accomplish here? I'm guessing you're trying to encode the URL? Either way, try this
# Change the parse_json method, this is safer. The way you had it would crash if data was invalid
def parse_json(response):
for item in response["reviews"]:
review_info = {
'film_title': item.get("mediaTitle", None),
'release_year': item.get("mediaInfo", None),
'full_review_url': item.get("url", None),
'review_date': item.get("date", None),
'rt_quote': item.get("quote", None),
'film_info_link': item.get("mediaUrl", None)}
reviews.append(review_info)
Change the loop to this or update your tokenize method.
for t in tokens:
data = main_request(baseurl, endpoint, t)
parse_json(data)
CodePudding user response:
Your tokenize function is the problem. You feed it (ex:"after=MA==") and it just gives you back the first letter 'a'. Just get rid of tokenize.
for t in tokens:
data = main_request(baseurl, endpoint, t)
parse_json(data)
This fixes your problem, but makes a new problem for you. Apparently, the keys you are getting from JSON, do not always exist. A simple fix is to refactor a bit. Using .get will either return the value or the second argument if the key does not exist.
def parse_json(response):
for item in response["reviews"]:
review_info = {
'film_title' : item.get("mediaTitle", None),
'release_year' : item.get("mediaInfo", None),
'full_review_url': item.get("url", None),
'review_date' : item.get("date", None),
'rt_quote' : item.get("quote", None),
'film_info_link' : item.get("mediaUrl", None)
}
reviews.append(review_info)
Your last token has a typo. after=OQ$.... should be after=OQ%....
If you are interested, I refactored your entire code. IMO, your code is unnecessarily fragmented, which is probably what led to your issues.
import requests
import pandas as pd
baseurl = "https://www.rottentomatoes.com/napi/critics/"
endpoint = "alison-willmore/movies?"
tokens = ("MA==", "MQ==", "Mg==", "Mw==", "NA==",
"NQ==", "Ng==", "Nw==", "OA==", "OQ==")
#filter
def filter_json(response):
for item in response["reviews"]:
yield {
'film_title' : item.get("mediaTitle", None),
'release_year' : item.get("mediaInfo" , None),
'full_review_url': item.get("url" , None),
'review_date' : item.get("date" , None),
'rt_quote' : item.get("quote" , None),
'film_info_link' : item.get("mediaUrl" , None)
}
#load
reviews = []
for t in tokens:
r = requests.get(f'{baseurl}{endpoint}after={t}')
for review in filter_json(r.json()):
reviews.append(review)
#use
d_frame = pd.DataFrame(reviews)
print(len(reviews))
print(d_frame.head(), d_frame.tail())