I'm building a regex to be able to parse addresses and am running into some blocks. An example address I'm testing against is:
5173B 63rd Ave NE, Lake Forest Park WA 98155
I am looking to capture the house number, street name(s), city, state, and zip code as individual groups. I am new to regex and am using regex101.com to build and test against, and ended up with:
(^\d \w?)\s((\w*\s?) ).\s(\w*\s?) ([A-Z]{2})\s(\d{5})
It matches all the groups I need and matches the whole string, but there are extra groups that are null value according to the match information (3 and 4). I've looked but can't find what is causing this issue. Can anyone help me understand?
CodePudding user response:
Your regex expression was almost good:
(^\d \w?)\s([\w*\s?] ).\s([\w*\s?] )\s([A-Z]{2})\s(\d{5})
What I changed are the second and third groups: in both you used a group inside a group ((\w*\s?) ), where a class inside a group (([\w*\s?] )) made sure you match the same things and you get the proper group content.
With your previous syntax, the inner group would be able to match an empty substring, since both quantifiers allow for a zero-length match (* is 0 to unlimited matches and ? is zero or one match). Since this group was repeated one or more times with the , the last occurrence would match an empty string and only keep that.
CodePudding user response:
For this you'll need to use a non-capturing group, which is of the form (?:regex), where you currently see your "null results". This gives you the regex:
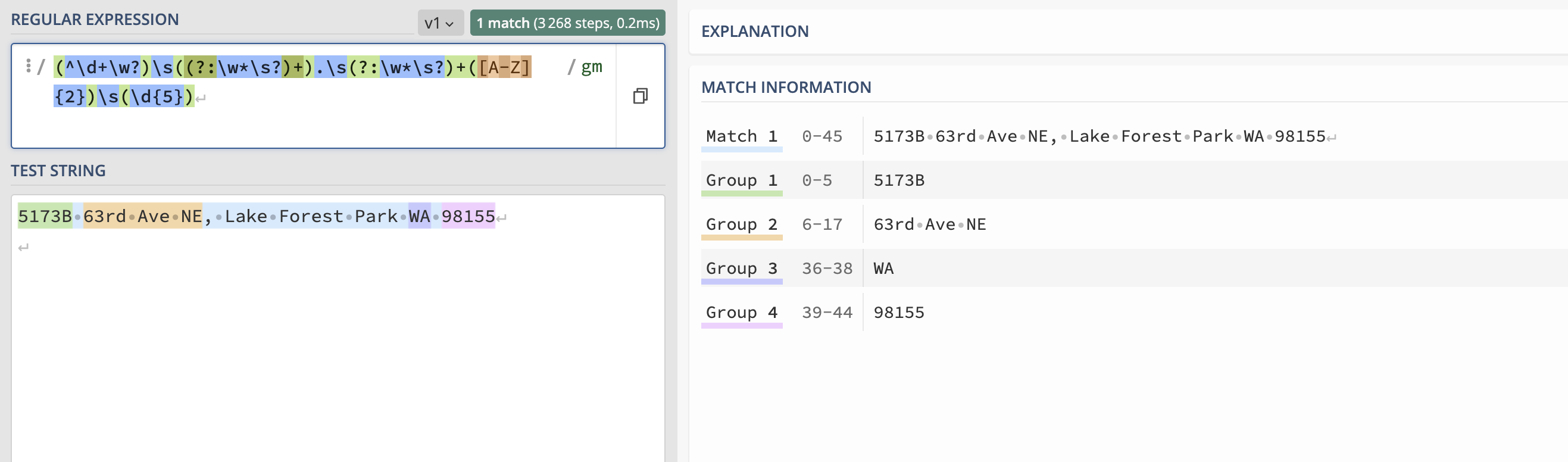
Here is a basic example of the difference between a capturing group and a non-capturing group:

See how the first group is captured into "Group 1" and the second one is not captured at all?
CodePudding user response:
Matching an address can be difficult due to the different formats.
If you can rely on the comma to be there, you can capture the part before it using a negated character class:
^(\d [A-Z]?)\s ([^,] ?)\s*,\s*(. ?)\s ([A-Z]{2})\s(\d{5})$Or take the part before the comma that ends on 2 or more uppercase characters, and then match optional non word characters using
\W*to get to the first word character after the comma:^(\d [A-Z]?)\s (.*?\b[A-Z]{2,}\b)\W*(. ?)\s ([A-Z]{2})\s(\d{5})$