I am trying to join two datasets, but they are not the same or have the same criteria.
Currently I have the dataset below, which contains the number of fires based on month and year, but the months are part of the header and the years are a column.
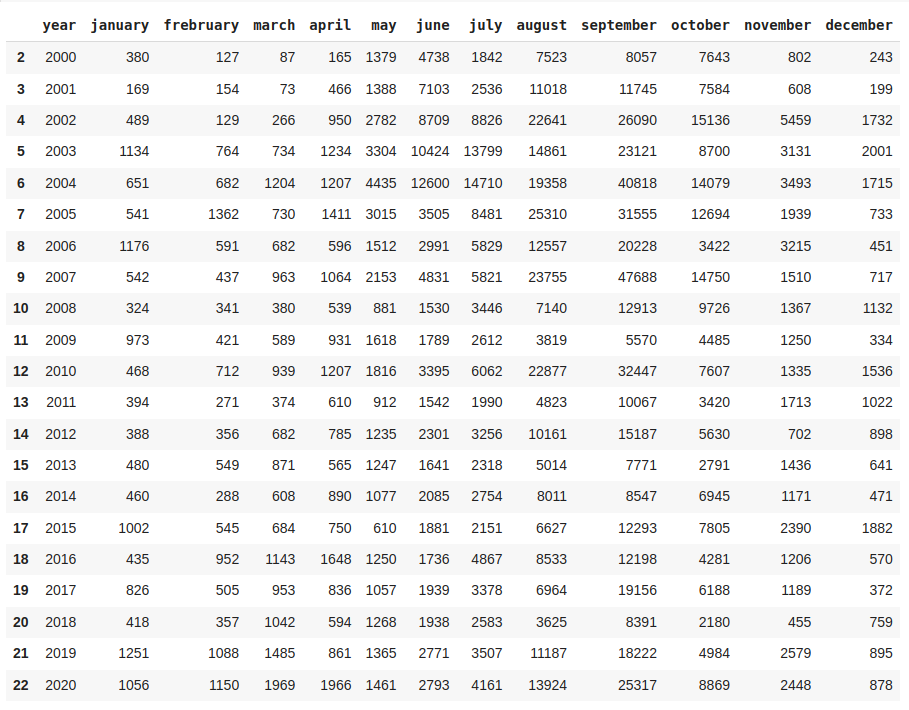
I would like to add this data, using as target data_medicao column from this other dataset, into a new column (let's hypothetically call it nr_total_queimadas).

The date format is YYYY-MM-DD, but the day doesn't really matter here.
I tried to make a loop of this case, but I think I'm doing something wrong and I don't have much idea how to proceed in this case.
Below an example of how I would like the output with the junction of the two datasets:

I used as an example the case where some dates repeat (which should happen) so the number present in the dataset that contains the number of fires, should also repeat.
CodePudding user response:
First, I assume that the first dataframe is in variable a and the second is in variable b.
To make looking up simpler, we set the index of a to year:
a = a.set_index('year')
Then, we take the years from the data_medicao in the dataframe b:
years = b['medicao'].dt.year
To get the month name from the dataframe b, we use strftime. Then we need to make the month name into lower case so that it matches the column names in a. To do that, we use .str.lower():
month_name_lowercase = b['medicao'].dt.strftime("%B").str.lower()
Then using lookup we can list all the values from dataframe a using indices years and month_name_lowercase:
num_fires = a.lookup(years.values, month_name_lowercase.values)
Finally add the new values into the new column in b:
b['nr_total_quimadas'] = num_fires
So the complete code is like this:
a = a.set_index('year')
years = b['medicao'].dt.year
month_name_lowercase = b['medicao'].dt.strftime("%B").str.lower()
num_fires = a.lookup(years.values, month_name_lowercase.values)
b['nr_total_queimadas'] = num_fires
CodePudding user response:
Assume following data for year vs month. Convert month names to numbers:
columns = ["year","jan","feb","mar"]
data = [
(2001,110,120,130),
(2002,210,220,230),
(2003,310,320,330)
]
df = pd.DataFrame(data=data, columns=columns)
month_map = {"jan":"1", "feb":"2", "mar":"3"}
df = df.rename(columns=month_map)
[Out]:
year 1 2 3
0 2001 110 120 130
1 2002 210 220 230
2 2003 310 320 330
Assume following data for datewise transactions. Extract year and month from date:
columns2 = ["date"]
data2 = [
("2001-02-15"),
("2001-03-15"),
("2002-01-15"),
("2002-03-15"),
("2003-01-15"),
("2003-02-15"),
]
df2 = pd.DataFrame(data=data2, columns=columns2)
df2["date"] = pd.to_datetime(df2["date"])
df2["year"] = df2["date"].dt.year
df2["month"] = df2["date"].dt.month
[Out]:
date year month
0 2001-02-15 2001 2
1 2001-03-15 2001 3
2 2002-01-15 2002 1
3 2002-03-15 2002 3
4 2003-01-15 2003 1
5 2003-02-15 2003 2
Join on year:
df2 = df2.merge(df, left_on="year", right_on="year", how="left")
[Out]:
date year month 1 2 3
0 2001-02-15 2001 2 110 120 130
1 2001-03-15 2001 3 110 120 130
2 2002-01-15 2002 1 210 220 230
3 2002-03-15 2002 3 210 220 230
4 2003-01-15 2003 1 310 320 330
5 2003-02-15 2003 2 310 320 330
Compute row-wise sum of months:
df2["nr_total_queimadas"] = df2[list(month_map.values())].apply(pd.Series.sum, axis=1)
df2[["date", "nr_total_queimadas"]]
[Out]:
date nr_total_queimadas
0 2001-02-15 360
1 2001-03-15 360
2 2002-01-15 660
3 2002-03-15 660
4 2003-01-15 960
5 2003-02-15 960