Is there a way to join 2 dataset without explode rows? I need only a flag if at least one row of dataset "df2" satisfies the join condition with the dataset of "df1".
Is there any way to avoid the join? I would like to avoid joining and then just keep the first row with a window function.
Condition left join is = [(df2.id == df1.id) & (df2.date >= df1.date)]
Example:
Input df1
| id | city | sport_event | date |
|---|---|---|---|
| abc | London | football | 2022-02-11 |
| def | Paris | volley | 2022-02-10 |
| ghi | Manchester | basketball | 2022-02-09 |
Input df2
| id | num_spect | date |
|---|---|---|
| abc | 100.000 | 2022-01-10 |
| abc | 200.000 | 2022-04-15 |
| abc | 150.000 | 2022-02-11 |
Output NOT DESIDERED <- NOT DESIDERED
| id | city | sport_event | date | num_spect |
|---|---|---|---|---|
| abc | London | football | 2022-02-11 | 100.000 |
| abc | London | football | 2022-02-11 | 200.000 |
| abc | London | football | 2022-02-11 | 150.000 |
| def | Paris | volley | 2022-02-10 | |
| ghi | Manchester | basketball | 2022-02-09 |
Output DESIDERED <- DESIDERED
| id | city | sport_event | date | num_spect | flag |
|---|---|---|---|---|---|
| abc | London | football | 2022-02-11 | 100.000 | 1 |
| def | Paris | volley | 2022-02-10 | ||
| ghi | Manchester | basketball | 2022-02-09 |
CodePudding user response:
Here's my implementation using left join
from pyspark.sql import functions as F
from pyspark.sql.types import *
from pyspark.sql import Window
df1 = spark.createDataFrame(
[
("abc", "London", "football", "2022-02-11"),
("def", "Paris", "volley", "2022-02-10"),
("ghi", "Manchester", "basketball", "2022-02-09"),
],
["id", "city", "sport_event", "date"],
)
df1 = df1.withColumn("date", F.col("date").cast(DateType()))
df2 = spark.createDataFrame(
[
("abc", "100.000", "2022-01-10"),
("abc", "200.000", "2022-04-15"),
("abc", "150.000", "2022-02-11"),
],
["id", "num_spect", "date"],
)
df2 = (df2
.withColumn("num_spect", F.col("num_spect").cast(DecimalType(18,3)))
.withColumn("date", F.col("date").cast(DateType()))
)
row_window = Window.partitionBy(
"df1.id",
"city",
"sport_event",
"df1.date",
).orderBy(F.col("num_spect").asc())
final_df = (
df1.alias("df1")
.join(
df2.alias("df2"),
on=(
(F.col("df1.id") == F.col("df2.id"))
& (F.col("df2.date") >= F.col("df1.date"))
),
how="left",
)
.withColumn(
"flag",
F.when(
F.col("df2.id").isNull(),
F.lit(None),
).otherwise(F.lit(1)),
)
.withColumn("row_num", F.row_number().over(row_window))
.filter(F.col("row_num") == 1)
.orderBy(F.col("df1.id"))
.drop(F.col("df2.id"))
.drop(F.col("df2.date"))
.drop(F.col("row_num"))
)
final_df.show()
OUTPUT:
--- ---------- ----------- ---------- --------- ----
| id| city|sport_event| date|num_spect|flag|
--- ---------- ----------- ---------- --------- ----
|abc| London| football|2022-02-11| 150.000| 1|
|def| Paris| volley|2022-02-10| null|null|
|ghi|Manchester| basketball|2022-02-09| null|null|
--- ---------- ----------- ---------- --------- ----
CodePudding user response:
Here are my 2 cents:
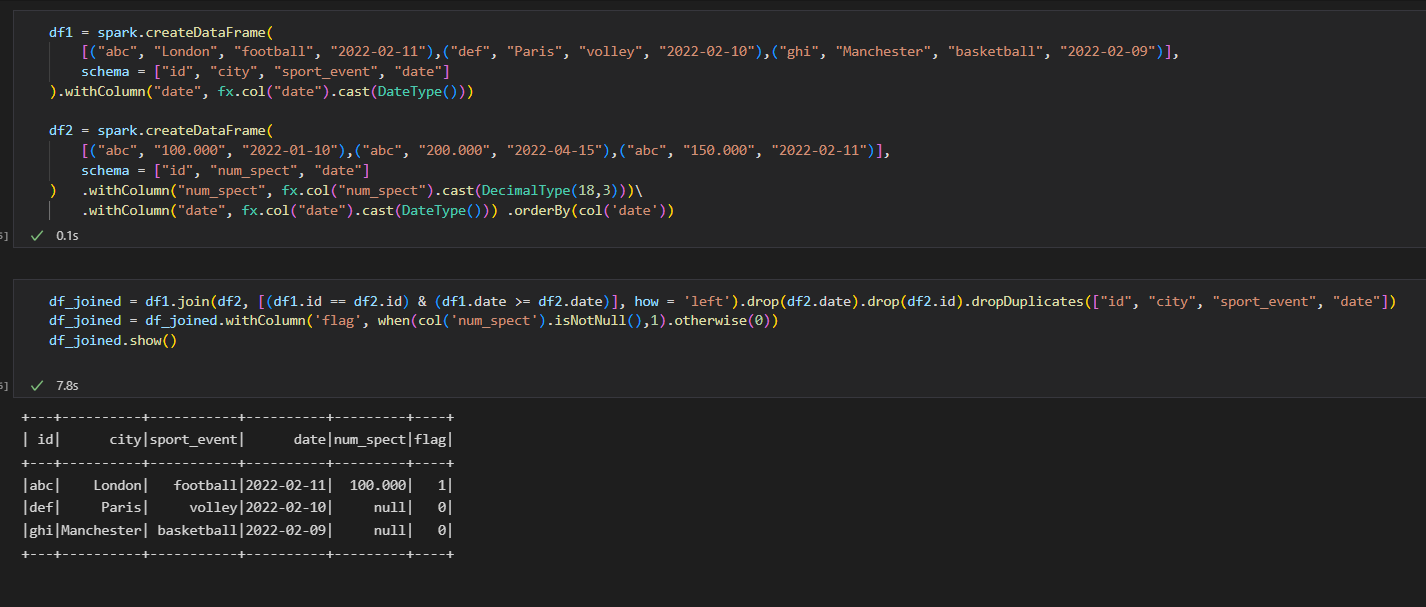
1.Create the data frames as follows:
df1 = spark.createDataFrame(
[("abc", "London", "football", "2022-02-11"),("def", "Paris", "volley", "2022-02-10"),("ghi", "Manchester", "basketball", "2022-02-09")],
schema = ["id", "city", "sport_event", "date"]
).withColumn("date", fx.col("date").cast(DateType()))
df2 = spark.createDataFrame(
[("abc", "100.000", "2022-01-10"),("abc", "200.000", "2022-04-15"),("abc", "150.000", "2022-02-11")],
schema = ["id", "num_spect", "date"]
) .withColumn("num_spect", fx.col("num_spect").cast(DecimalType(18,3)))\
.withColumn("date", fx.col("date").cast(DateType())) .orderBy(col('date'))
Then join based on the condition and then drop duplicates, finally update the column flag based on num_spect value:
df_joined = df1.join(df2, [(df1.id == df2.id) & (df1.date >= df2.date)], how = 'left').drop(df2.date).drop(df2.id).dropDuplicates(["id", "city", "sport_event", "date"]) df_joined = df_joined.withColumn('flag', when(col('num_spect').isNotNull(),1).otherwise(0))Print the data frame df_joined.show()
Please refer the below screenshot for your reference: