I have a dataframe df like below :
import pandas as pd
data = {'A': ['ABCD_1', 'ABCD_1', 'ABCD_1', 'ABCD_1', 'PQRS_2', 'PQRS_2', 'PQRS_2', 'PQRS_2', 'PQRS_2', 'PQRS_3', 'PQRS_4'], 'B':[2, 3, 5, 6, 7, 8, 9, 11, 13, 15, 17]}
df = pd.DataFrame(data)
df
| A | B |
------------ ----------
| ABCD_1 | 2 |
| ABCD_1 | 3 |
| ABCD_1 | 5 |
| ABCD_1 | 6 |
| PQRS_2 | 7 |
| PQRS_2 | 8 |
| PQRS_2 | 9 |
| PQRS_2 | 11 |
| PQRS_2 | 13 |
| PQRS_3 | 15 |
| PQRS_4 | 17 |
------------ ----------
What I want to achieve is that I need to assign 1 to first value of every group of column A and 0 to the rest of other values. Incase, there is a single group present in Column A I just assign 1 to that group. So, my expected result should look like below.
Expected Output :
| A | B | P |
------------ ---------- ----------
| ABCD_1 | 2 | 1 |
| ABCD_1 | 3 | 0 |
| ABCD_1 | 5 | 0 |
| ABCD_1 | 6 | 0 |
| PQRS_2 | 7 | 1 |
| PQRS_2 | 8 | 0 |
| PQRS_2 | 9 | 0 |
| PQRS_2 | 11 | 0 |
| PQRS_2 | 13 | 0 |
| PQRS_3 | 15 | 1 |
| PQRS_4 | 17 | 1 |
------------ ---------- ----------
I tried to group them using the below code, however, I wasn't able to get expected results.
Actual Output
df['P'] = pd.factorize(df['A']) 1
| A | B | P |
------------ ---------- ----------
| ABCD_1 | 2 | 1 |
| ABCD_1 | 3 | 1 |
| ABCD_1 | 5 | 1 |
| ABCD_1 | 6 | 1 |
| PQRS_2 | 7 | 1 |
| PQRS_2 | 8 | 2 |
| PQRS_2 | 9 | 2 |
| PQRS_2 | 11 | 2 |
| PQRS_2 | 13 | 2 |
| PQRS_3 | 15 | 3 |
| PQRS_4 | 17 | 4 |
------------ ---------- ----------
How can I assign 1 and 0 to each of the groups using Pandas ?
CodePudding user response:
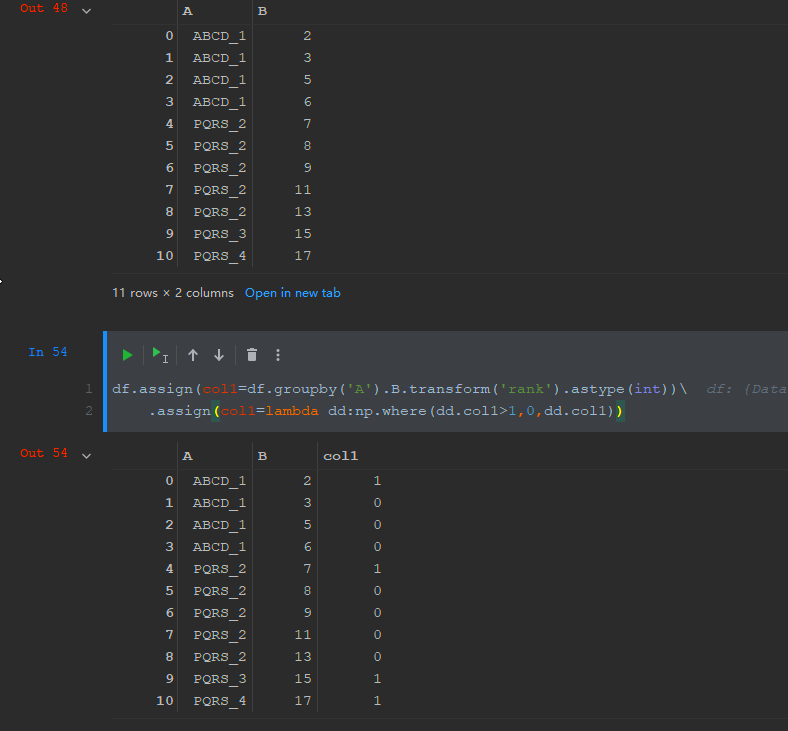
You could achieve this as follows:
- Use
be sure to answer the question. Provide details and share research!