I want to build a model that classifies and predicts words from the users lips. With adverb a total of 142657 images that have been preproccessed using the dataset of videos of individual speakers but I get this error when running the model and doesnt even get past the first epoch heres my code
import os
from silence_tensorflow import silence_tensorflow
silence_tensorflow()
import tensorflow as tf
from tensorflow.keras.layers import Dense, Activation, Dropout, Input, Conv2D, \
MaxPooling2D, Flatten, BatchNormalization
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.image import ImageDataGenerator
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
tf.autograph.set_verbosity(0)
tf.get_logger().setLevel('ERROR')
class AdverbNet(object):
def __init__(self):
self.Model = Sequential()
self.build()
def build(self):
self.Model.add(Input(name='the_input', shape=(224, 224, 1), batch_size=16, dtype='float32'))
self.Model.add(Conv2D(32, (3, 3), activation='sigmoid', name='convo2'))
self.Model.add(MaxPooling2D(pool_size=(2, 2)))
self.Model.add(Conv2D(32, (3, 3), activation='sigmoid', name='convo3'))
self.Model.add(MaxPooling2D(pool_size=(2, 2)))
self.Model.add(Conv2D(64, (3, 3), activation='relu', name='convo4'))
self.Model.add(MaxPooling2D(pool_size=(2, 2)))
self.Model.add(Flatten())
self.Model.add(Dense(512))
self.Model.add(Dropout(0.5))
self.Model.add(BatchNormalization(scale=False))
self.Model.add(Activation('relu'))
self.Model.add(Dropout(0.5))
self.Model.add(Dense(4, activation='softmax'))
def summary(self):
self.Model.summary()
if __name__ == "__main__":
common_path = 'C:/Users/Loide/Desktop/Liphy/'
C = AdverbNet()
C.Model.compile(optimizer="Adam", loss='categorical_crossentropy', metrics=['accuracy'])
C.Model.summary()
with tf.device('/device:GPU:0')
batch_size = 16
epochs = 32
train_dir = common_path 'Images/Adverb/'
test_dir = common_path 'Images/Adverb/'
checkpoint_path = common_path 'SavedModels/Adverb/'
train_image_generator = ImageDataGenerator(rescale=1. / 255) # Generator for training data generate training anD test set
train_data_gen = train_image_generator.flow_from_directory(batch_size=batch_size,
directory=train_dir,
shuffle=True,
target_size=(224, 224),
class_mode='categorical',
color_mode='grayscale')
test_image_generator = ImageDataGenerator(rescale=1. / 255) # Generator for test data
test_data_gen = test_image_generator.flow_from_directory(batch_size=batch_size,
directory=test_dir,
shuffle=False,
target_size=(224, 224),
class_mode='categorical',
color_mode='grayscale')
callback = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy',
patience=10,
restore_best_weights=True,
baseline=0.45)
history = C.Model.fit(train_data_gen,
steps_per_epoch=8916, # Number of images // Batch size
epochs=epochs,
verbose=1,
validation_data=test_data_gen,
validation_steps=187,
callbacks=[callback])
C.Model.save(checkpoint_path, save_format='tf')
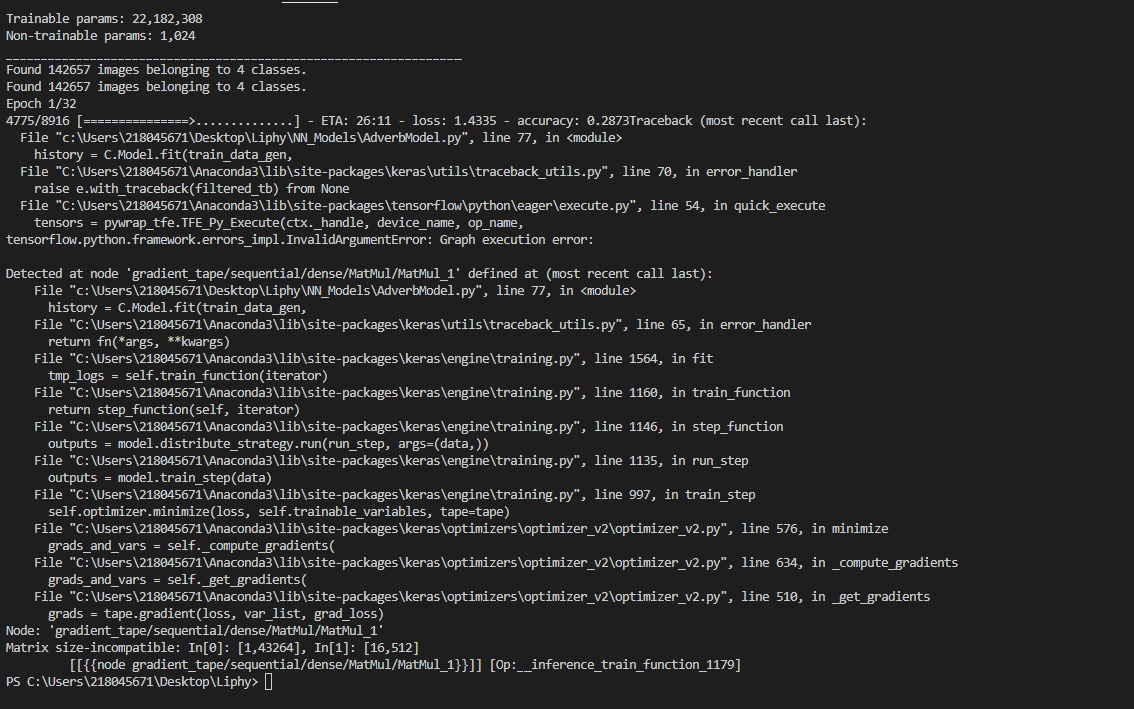
**and I get the following error **
[Matrix size-incompatible: In[0]: [1,43264], In[1]: [16,512]
[[{{node gradient_tape/sequential/dense/MatMul/MatMul_1}}]] [Op:__inference_train_function_1179]
CodePudding user response:
Seems like you have two matrices (one 1x43265 and one 16x512). You try to multiply them but its product is mathematically not defined. You need one matrix to be a (a x b) matrix and the other to be a (b x c) matrix. Thats why your program can't run. If your images are a test dataset try to follow the instructions step by step. If not, your preprocessing is probably bad.
CodePudding user response:
It is easy you need to match the output to the loss function and target categorize see my updates examples.
Sample:
import os
from silence_tensorflow import silence_tensorflow
silence_tensorflow()
import tensorflow as tf
from tensorflow.keras.layers import Dense, Activation, Dropout, Input, Conv2D, \
MaxPooling2D, Flatten, BatchNormalization
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.image import ImageDataGenerator
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Variables
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
tf.autograph.set_verbosity(0)
tf.get_logger().setLevel('ERROR')
BATCH_SIZE = 1
IMG_HEIGHT = 32
IMG_WIDTH = 32
IMG_CHANNELS=1
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Class and Functions
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
class AdverbNet(object):
def __init__(self):
self.Model = Sequential()
self.build()
def build(self):
model = tf.keras.models.Sequential([
tf.keras.layers.InputLayer(input_shape=( 1,IMG_HEIGHT, IMG_WIDTH, 1 )),
tf.keras.layers.Reshape((IMG_HEIGHT, IMG_WIDTH, 1)),
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
tf.keras.layers.Normalization(mean=3., variance=2.),
tf.keras.layers.Normalization(mean=4., variance=6.),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.Reshape((30, 30, 32)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Reshape((128, 225)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(96, return_sequences=True, return_state=False)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(96)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(192, activation='relu'),
tf.keras.layers.Dense(10),
])
self.Model = model
def summary(self):
self.Model.summary()
if __name__ == "__main__":
common_path = ''
C = AdverbNet()
###
C.Model.compile(optimizer="Adam", loss='SparseCategoricalCrossentropy', metrics=['accuracy'])
C.Model.summary()
with tf.device('/device:GPU:0') :
batch_size = 16
epochs = 32
train_dir = common_path 'F:\\datasets\\downloads\\Actors\\train'
test_dir = common_path 'F:\\datasets\\downloads\\Actors\\validation'
checkpoint_path = common_path 'F:\\models\\checkpoint\\temp'
train_image_generator = ImageDataGenerator(rescale=1. / 255) # Generator for training data generate training and test set
train_data_gen = train_image_generator.flow_from_directory(batch_size=batch_size,
directory=train_dir,
shuffle=True,
target_size=(32, 32),
###class_mode='categorical',
class_mode='binary',
### class_mode='sparse', # None # categorical # binary # sparse
color_mode='grayscale')
test_image_generator = ImageDataGenerator(rescale=1. / 255) # Generator for test data
test_data_gen = test_image_generator.flow_from_directory(batch_size=batch_size,
directory=test_dir,
shuffle=False,
target_size=(32, 32),
###class_mode='categorical',
class_mode='binary',
### class_mode='sparse', # None # categorical # binary # sparse
color_mode='grayscale')
callback = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy',
patience=10,
restore_best_weights=True,
baseline=0.45)
history = C.Model.fit(train_data_gen,
steps_per_epoch=8916, # Number of images // Batch size
epochs=epochs,
verbose=1,
validation_data=test_data_gen,
validation_steps=187,
callbacks=[callback])
C.Model.save(checkpoint_path, save_format='tf')
Output:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
reshape (Reshape) (None, 32, 32, 1) 0
random_flip (RandomFlip) (None, 32, 32, 1) 0
random_rotation (RandomRota (None, 32, 32, 1) 0
tion)
normalization (Normalizatio (None, 32, 32, 1) 0
n)
normalization_1 (Normalizat (None, 32, 32, 1) 0
ion)
conv2d (Conv2D) (None, 30, 30, 32) 320
reshape_1 (Reshape) (None, 30, 30, 32) 0
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
dense (Dense) (None, 15, 15, 128) 4224
reshape_2 (Reshape) (None, 128, 225) 0
bidirectional (Bidirectiona (None, 128, 192) 247296
l)
bidirectional_1 (Bidirectio (None, 192) 221952
nal)
flatten (Flatten) (None, 192) 0
dense_1 (Dense) (None, 192) 37056
dense_2 (Dense) (None, 10) 1930
=================================================================
Total params: 512,778
Trainable params: 512,778
Non-trainable params: 0
_________________________________________________________________
Found 46 images belonging to 2 classes.
Found 33 images belonging to 2 classes.
Epoch 1/32
8916/8916 [==============================] - 13s 459us/step - loss: 4.1638 - accuracy: 0.2826 - val_loss: 0.7410 - val_accuracy: 0.5455