How can I access the content inside the highlighted class (image bellow)? I am trying to print all comments from a TikTok video (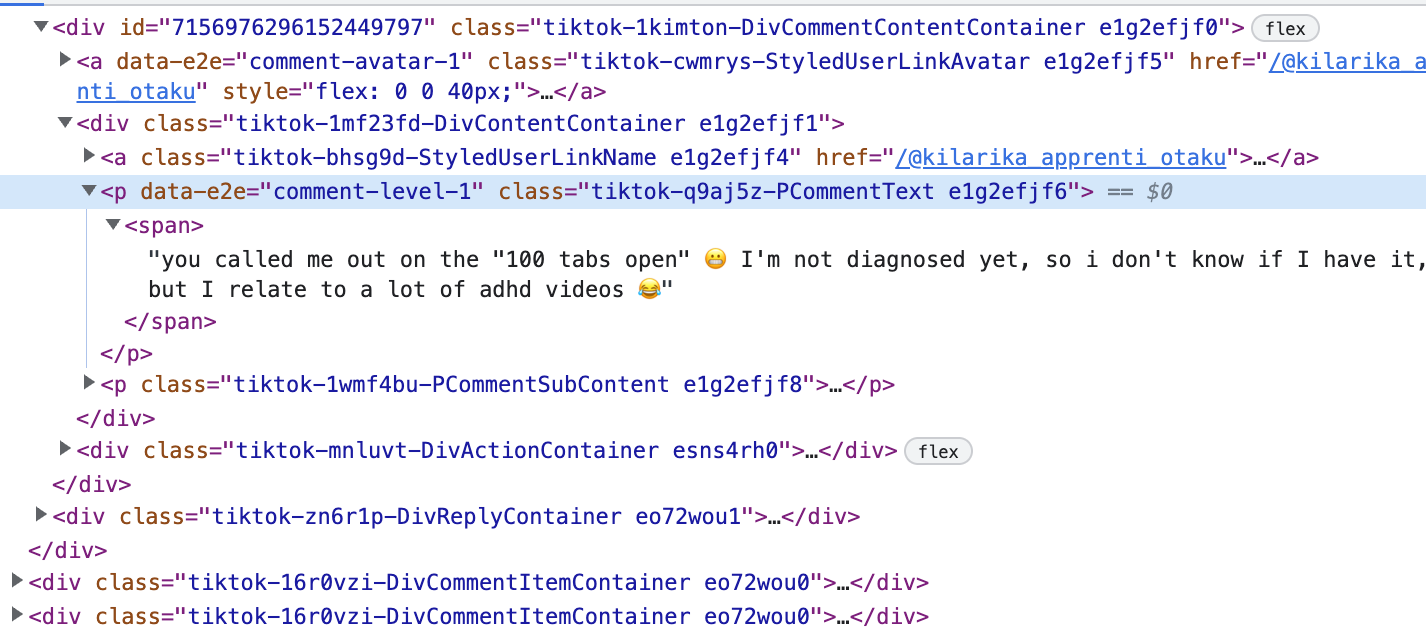
CodePudding user response:
First of all I'll point you to some issues you have within the code, your trying to find an element by it's xpath that's always changing, thus the Simpler way is to find some class name thats 'static' so you can loop through it and get all comments!!
#change this
element = browser.find_element_by_xpath('//*[@id="7156976296152449797"]/div[1]/p[1]')
#to this => and notice the element(s) not element
element = driver.find_elements_by_xpath('//div[contains(@class, "DivContentContainer")]/p[1]')
for elem in element:
print(elem.text)
- Nt : I Tested the code and it's retrieving all the comments you set the scrollHeight to !!!. Thus, to get Further comments include
time.sleep() or WebDriverWait()before scrolling bellow to get more Comments. - The 'Replies' are not included, Since you have to check if every comment has replies, if no skip every time.
CodePudding user response:
You just need to target the part of the class that does not change - the CommentContent, and CommentText parts.
In bs4, select with css selectors is great for targeting nested tags, or tags by partial attributes:
containers = soup.select('div[class*="CommentContent"]') # comment content
commentItems = soup.select('div[class*="CommentItem"]') # outermost comment containers
commentTexts = soup.select('div[class*="CommentContent"] p[class*="CommentText"]') # same as find_all('p',{'data-e2e':'comment-level-1'})
commenterNames = soup.select('div[class*="CommentContent"] span[class*="UserName"]') # usernames of commenters
The same elements can be targeted with selenium and xpath
containers = browser.find_element_by_xpath('//div[contains(@class, "CommentContent")]')
commentItems = browser.find_element_by_xpath('//div[contains(@class, "CommentItem")]')
commentTexts = browser.find_element_by_xpath('//div[contains(@class, "CommentContent")]//p[contains(@class, "CommentText")]')
commenterNames = browser.find_element_by_xpath('//div[contains(@class, "CommentContent")]//span[contains(@class, "UserName")]')