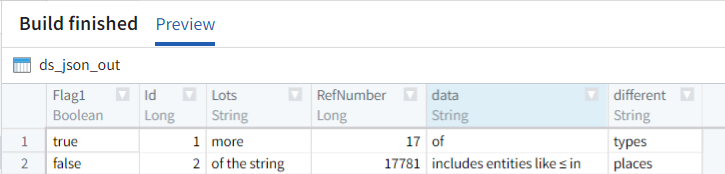
I am analysing some JSON data in Palantir Foundry using PySpark. The source is a 30MB uploaded JSON file containing four elements, one of which holds a table of some 60 columns and 20,000 rows. Some of the columns in this table are strings that contain HTML entities representing UTF characters (other columns are numeric or boolean). I want to clean these strings to replace the HTML entities with the corresponding characters.
I realise that I can apply html.unescape(my_str) in a UDF to the string columns once all the JSON data has been converted into dataframes. However, this sounds inefficient.