I have stopwords for brazilian portuguese configured at my index. but if I made a search for the term "ios" (it's a ios course), a bunch of other documents are returned, because the term "nos" (brazilian stopword) seems to be identified as a valid term for the fuzzy query.
But if I search just by the term "nos", nothing is returned. I would be not expected ios course to be returned by fuzzy query? I'm confused.
Is there any alternative to this. The main purpose here is that when user search for ios, the documents with stopword like "nos" won't be returned, while I can mantain the fuzziness for other more complex search made by users.
An example of query:
GET /index/_search
{
"explain": true,
"query": {
"bool" : {
"must" : [
{
"terms" : {
"document_type" : [
"COURSE"
],
"boost" : 1.0
}
},
{
"multi_match" : {
"query" : "ios",
"type" : "best_fields",
"operator" : "OR",
"slop" : 0,
"fuzziness" : "AUTO",
"prefix_length" : 0,
"max_expansions" : 50,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"fuzzy_transpositions" : true,
"boost" : 1.0
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}
part of explain query:
"description": "weight(corpo:nos in 52) [PerFieldSimilarity], result of:",
image with the config of stopwords
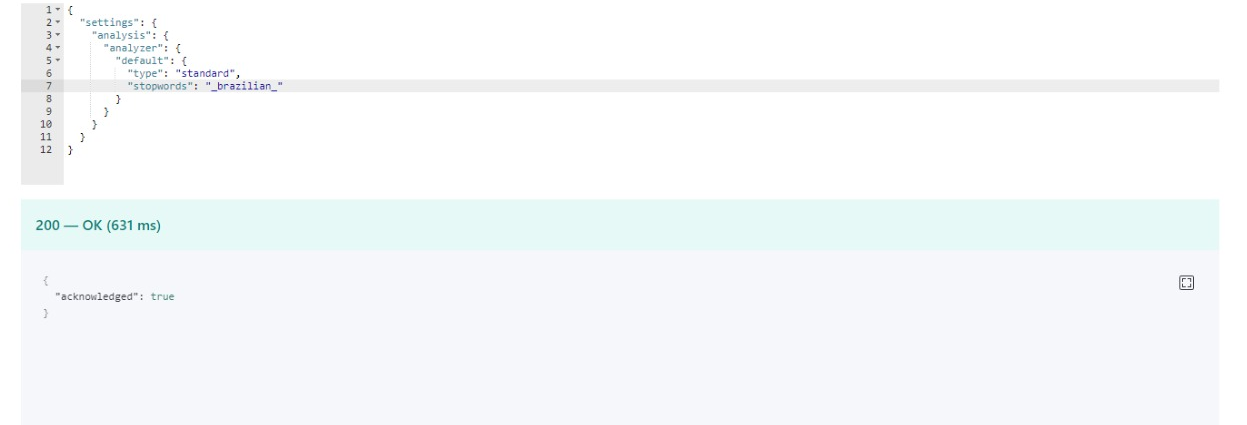
thanks
I tried to add the prefix length, but I want that stopwords to be ignored.
CodePudding user response:
I believe that correctly way to work stopwords by language is below:
PUT idx_teste
{
"settings": {
"analysis": {
"filter": {
"brazilian_stop_filter": {
"type": "stop",
"stopwords": "_brazilian_"
}
},
"analyzer": {
"teste_analyzer": {
"tokenizer": "standard",
"filter": ["brazilian_stop_filter"]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "teste_analyzer"
}
}
}
}
POST idx_teste/_analyze
{
"analyzer": "teste_analyzer",
"text":"course nos advanced"
}
Look term "nos" was removed.
{
"tokens": [
{
"token": "course",
"start_offset": 0,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "advanced",
"start_offset": 11,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 2
}
]
}