I am trying to ingest 2 csv files into a single spark dataframe. However, the schema of these 2 datasets is very different, and when I perform the below operation, I get back only the schema of the second csv, as if the first one doesn't exist. How can I solve this? My final goal is to count the total number of words.
paths = ["abfss://lmne.dfs.core.windows.net/csvs/MachineLearning_reddit.csv", "abfss://[email protected]/csvs/bbc_news.csv"]
df0_spark=spark.read.format("csv").option("header","false").load(paths)
df0_spark.write.mode("overwrite").saveAsTable("ML_reddit2")
df0_spark.show()
I tried to load both of the files into a single spark dataframe, but it only gives me back one of the tables.
CodePudding user response:
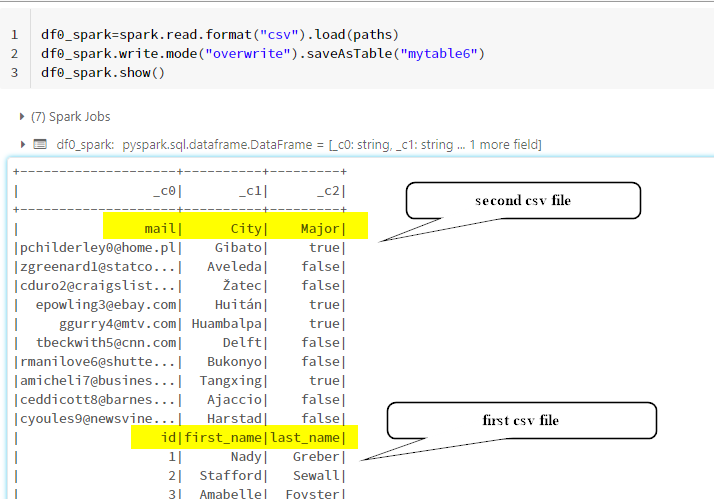
I have reproduced the above and got the below results.
For sample, I have two csv files in dbfs with different schemas. when I execute the above code, I got the same result.
To get the desired schema enable mergeSchemaand header while reading the files.
Code:
df0_spark=spark.read.format("csv").option("mergeSchema","true").option("header","true").load(paths)
df0_spark.show()
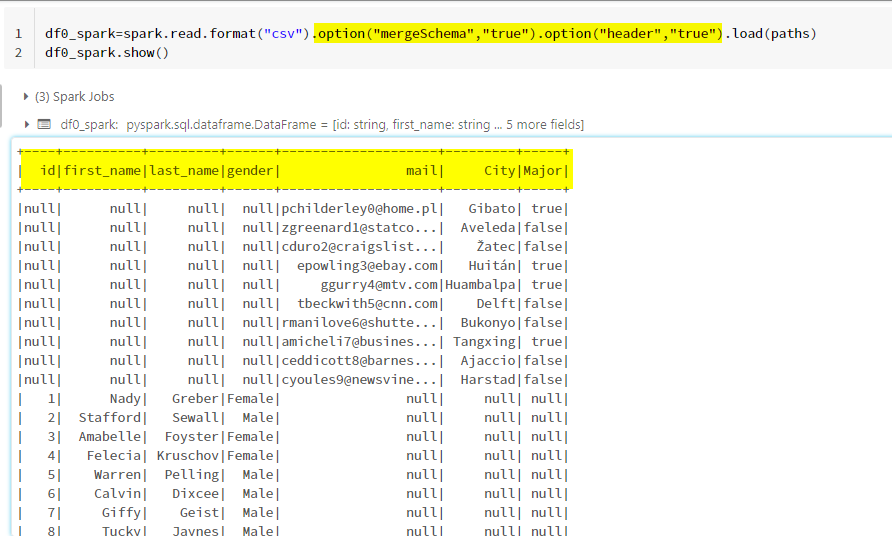
If you want to combine the two files without nulls, we should have a common identity column and we have to read the files individually and use inner join for that.
CodePudding user response:
The solution that has worked for me the best in such cases was to read all distinct files separately, and then union them after they have been put into DataFrames. So your code could look something like this:
paths = ["abfss://lmne.dfs.core.windows.net/csvs/MachineLearning_reddit.csv", "abfss://[email protected]/csvs/bbc_news.csv"]
# Load all distinct CSV files
df1 = spark.read.option("header", false).csv(paths[0])
df2 = spark.read.option("header", false).csv(paths[1])
# Union DataFrames
combined_df = df1.unionByName(df2, allowMissingColumns=True)
Note: if the names of columns differ between the files, then for all columns from first file that are not present in second one, you will have null values. If the schema should be matching, then you can always rename the columns, before the unionByName step.