I am trying to scrape the website 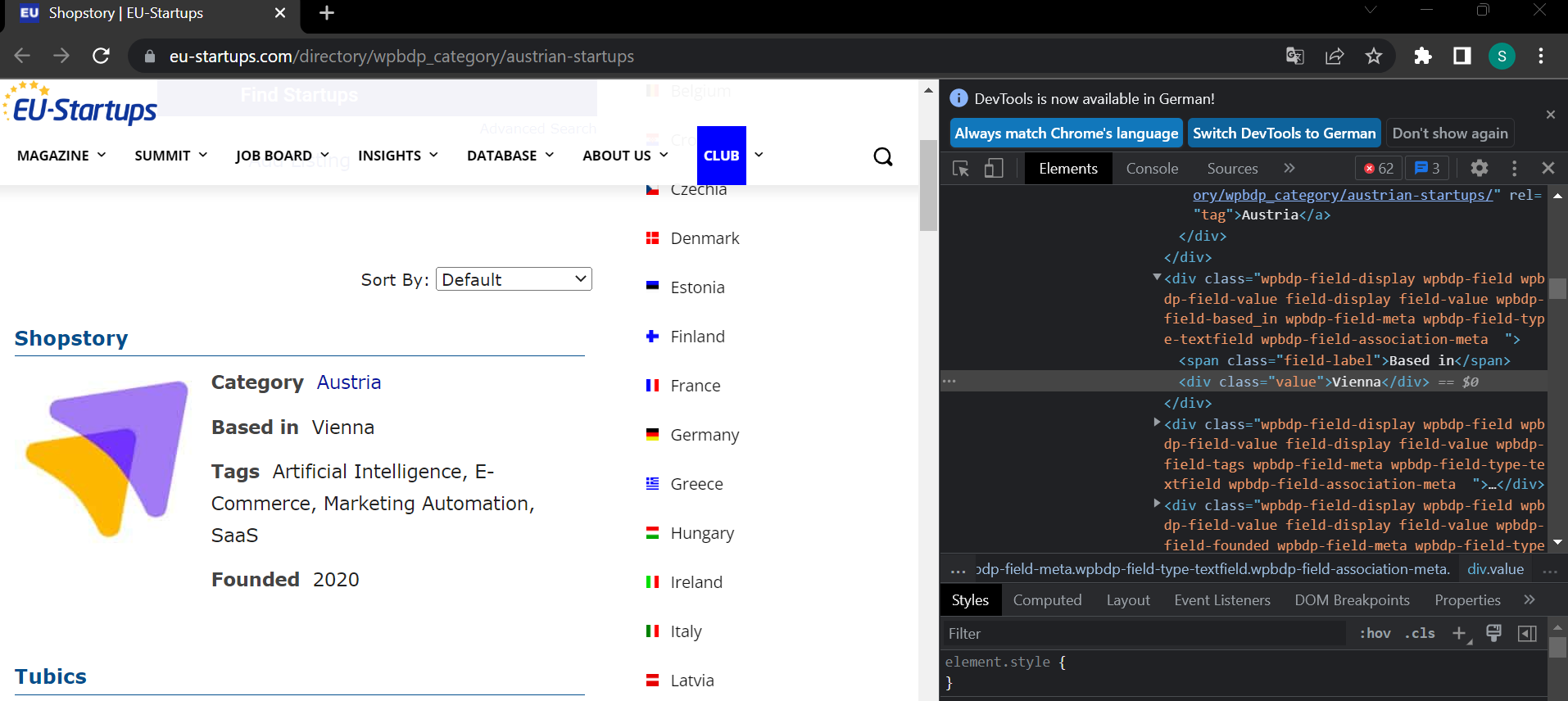
CodePudding user response:
Try:
import requests
from bs4 import BeautifulSoup
url = "https://www.eu-startups.com/directory/wpbdp_category/austrian-startups/page/1/"
soup = BeautifulSoup(requests.get(url).content, "html.parser")
for l in soup.select(".wpbdp-listing"):
title = l.a.text
based = l.select_one("span:-soup-contains(Based) div").text
tags = l.select_one("span:-soup-contains(Tags) div").text.split(", ")
founded = l.select_one("span:-soup-contains(Founded) div").text
print(title, based, founded)
print(tags)
print()
Prints:
Shopstory Vienna 2020
['Artificial Intelligence', 'E-Commerce', 'Marketing Automation', 'SaaS']
Tubics Vienna 2017
['Advertising', 'SaaS', 'Software', 'Video', 'VideoEditing']
25superstars Vienna 2020
['content creator', 'social media']
myCulture GmbH Vienna 2022
['CultTech', 'marketplace', 'big data']
And-Less Wien 2022
['Packaging', 'Plastic waste', 'Circular economy', 'Sustainable']
heyqq – ask away Vienna 2022
['audio', 'social', 'app']
NXRT Wien 2022
['Artificial Intelligence', 'Automotive', 'Autonomous Vehicles', 'Education', 'Enterprise Software', 'Information Technology', 'Railroad', 'Software', 'Software Engineering']
ReDev Vienna 2022
['Information Technology', 'Recruiting', 'SaaS', 'Software']
Revitalyze Innsbruck 2022
['Building Material', 'Green Building', 'Logistics', 'Marketplace', 'Recycling', 'Waste Management']
Coachfident Vienna 2022
['coaching', 'personal development', 'career coaching']
Goddard – Discovery Hagenberg 2022
['Artificial Intelligence', 'Machine Learning', 'Application Development']