I have the following dataframe:
id phone email
10352897
10352897 10225967
10352897 [email protected]
10352897 10225967 [email protected]
10225967
10225967 [email protected]
[email protected]
23578910
23578910 38256789
23578910 [email protected]
23578910 38256789 [email protected]
38256789
38256789 [email protected]
[email protected]
65287930 [email protected]
65287930
[email protected]
65287930
70203065
70203065
70203065
[email protected]
[email protected]
[email protected]
Not all the fields are always filled in, but they are related to each other in at least one column.
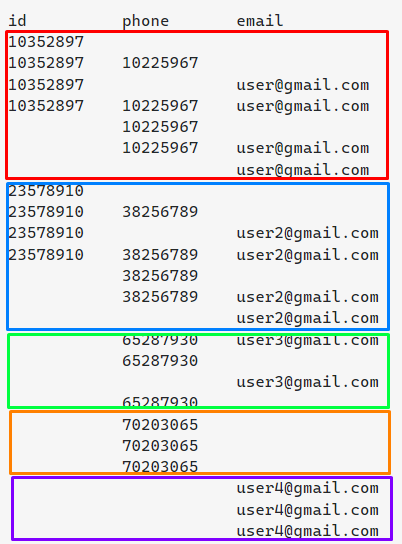
I would like that when it coincides in at least one of the three columns, the record joins and prioritizes the filled fields over the empty ones, in the end in this example I would expect the following output:
id phone email
10352897 10225967 [email protected]
23578910 38256789 [email protected]
65287930 [email protected]
70203065
[email protected]
How would you go about doing this?
CodePudding user response:
This is quite a specific requirement and I'm not aware of any in-built pandas function that does what you're looking for, so I tried to define exactly what you are looking to do and recreate it from scratch.
The best I could come up with is that reading from the top of the dataframe, we will look at the values in each of the columns until we find a row with a value in a column that is different from the previously encountered value in that column, at which point we put all the values encountered so far into a row in the new dataframe.
This looks like (assuming your original dataframe is named df and the empty cells are blanks (''):
new_rows = []
# Create a dictionary where keys are the columns of the original df
new_row = {col: '' for col in df.columns}
# Iterate over rows
for _, row in df.iterrows():
# Iterate over columns in row
for col in row.keys():
# If this column is not blank
if row[col]:
# If this column has already been filled in the new row
# and the value is different, add this row to the new dataframe
if new_row[col] and new_row[col] != row[col]:
new_rows.append(new_row)
new_row = {col: '' for col in df.columns}
# Otherwise, set this value for the current row of the new dataframe
else:
new_row[col] = row[col]
# Add the last row
new_rows.append(new_row)
new_df = pd.DataFrame(new_rows)
print(new_df)
However, 70203065 and [email protected] end up in the same row in the new dataframe:
id phone email
0 10352897 10225967 [email protected]
1 23578910 38256789 [email protected]
2 65287930 [email protected]
3 70203065 [email protected]
You may need to think about what the logic is that causes 70203065 and [email protected] to end up in separate rows, but hopefully this gets you started in the right direction.
CodePudding user response:
If the goal is solely to obtain the desired output, one approach would be to get a dataframe with unique values of each column in the original dataframe df, and for that, one can use pandas.DataFrame.apply with a custom lambda function as follows
df_new = df.apply(lambda x: pd.Series(x.unique()[~pd.isnull(x.unique())]))
[Out]:
id phone email
0 10352897.0 10225967.0 [email protected]
1 23578910.0 38256789.0 [email protected]
2 NaN 65287930.0 [email protected]
3 NaN 70203065.0 [email protected]
Then, even though there is room to implement a validation to check if, for a given unique value, the rest of the columns match in the df, as in this specific case the first three rows are actually correct, we won't consider that. One will simply duplicate the last row
df_new = pd.concat([df_new, df_new.iloc[-1:]], ignore_index=True)
Then adjust the respective values to obtain the desired output
df_new.iloc[-2,2] = np.nan
df_new.iloc[-1,1] = np.nan
[Out]:
id phone email
0 10352897.0 10225967.0 [email protected]
1 23578910.0 38256789.0 [email protected]
2 NaN 65287930.0 [email protected]
3 NaN 70203065.0 NaN
4 NaN NaN [email protected]
Notes:
Even though the final part is not the most elegant, and require some "manual" work (duplicating a row and manually changing the cell values), this works for OP's specific case.
There are strong opinions on using
.apply(). For that, one might want to read this.
CodePudding user response:
here is one way to do it.
please note: the third section in your question, don't follow your stated pattern coincides in at least one of the three columns,
# Compare each rows with the next and identify ones where all three columns have changed
df['keep']=((df['id'].ne(df['id'].shift(-1)) &
df['phone'].ne(df['phone'].shift(-1)) &
df['email'].ne(df['email'].shift(-1))
))
# map
df['chng']=df['keep'].map({False : np.nan, True: 1})
# cumsum to find the number of groups
df['chng']=df['chng'].cumsum().bfill()
# groupby and fill values
df=df.groupby('chng', as_index=True).ffill()
# keep the ones where values have changed
out=df.loc[df['keep']==True].fillna('')[['id','phone','email']]
out
id phone email
6 10352897.0 10225967.0 [email protected]
13 23578910.0 38256789.0 [email protected]
15 65287930.0 [email protected]
16 [email protected]
17 65287930.0
20 70203065.0
23 [email protected]
though, if you run the above code again, it further consolidates the middle three rows into your expected resultset
id phone email
6 10352897.0 10225967.0 [email protected]
13 23578910.0 38256789.0 [email protected]
17 65287930.0 [email protected]
20 70203065.0
23 [email protected]