Hi guys,
I am basically new to coding in general so bare with me.
I am trying to retrieve the table headers for this table:
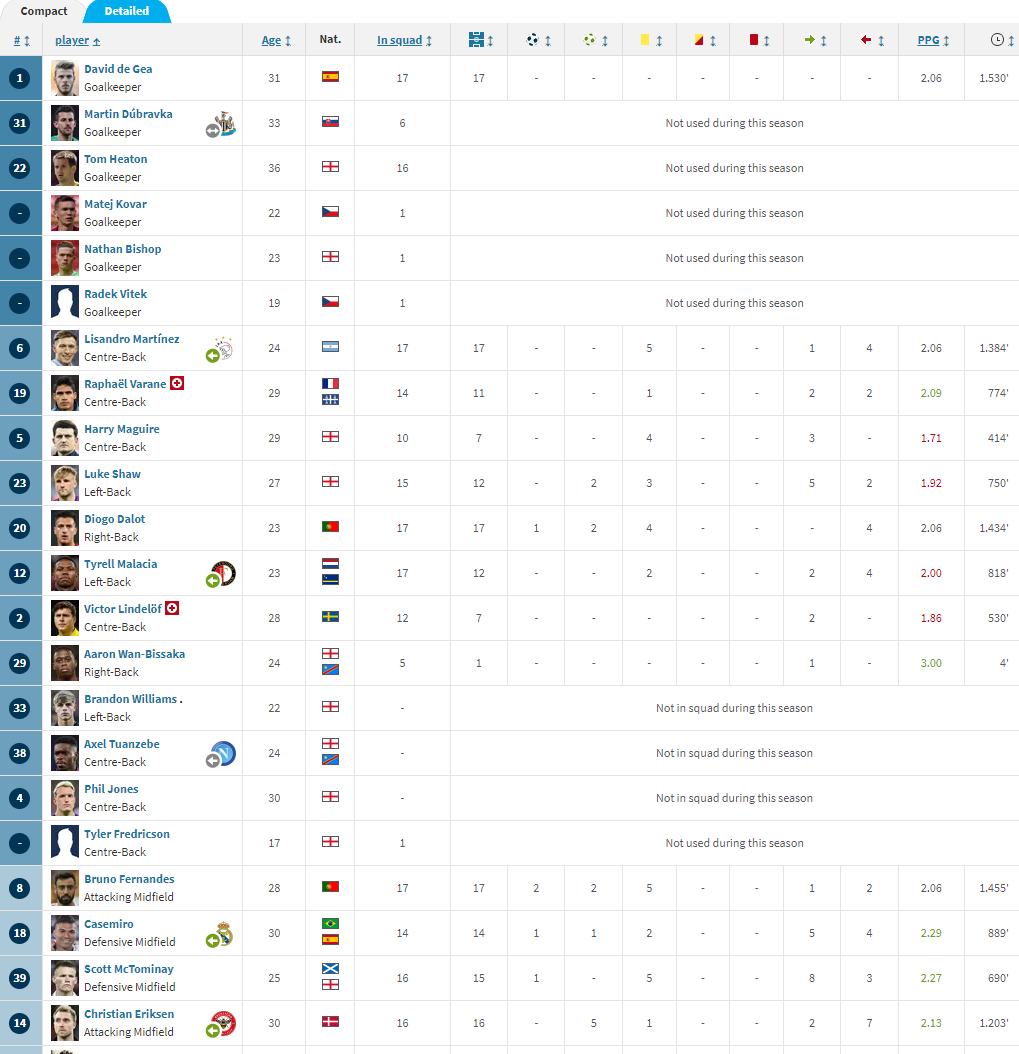
First i tried with pandas but i could not get my data so i learned about beautifull soup and tried my luck with it.
The problem is that some headers are text and i could get the info pretty easily using this:
from bs4 import BeautifulSoup as bs
import requests
url = 'https://www.transfermarkt.co.uk/manchester-united-fc/leistungsdaten/verein/985/reldata/&2022/plus/1'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}
response = requests.get(url, headers=headers)
response.content
soup = bs(response.content, 'html.parser')
soup.prettify().splitlines()
tabela_equipa = soup.find('table', {'class': 'items'} )
headers_tabela = [th.text.encode("utf-8") for th in tabela_equipa.select("tr th")]
print(headers_tabela)
Output: [b'#', b'player', b'Age', b'Nat.', b'In squad', b'\xc2\xa0', b'\xc2\xa0', b'\xc2\xa0', b'\xc2\xa0', b'\xc2\xa0', b'\xc2\xa0', b'\xc2\xa0', b'\xc2\xa0', b'PPG', b'\xc2\xa0']
The thing is that most of those headers are icons and the info i need is actually in the span title, and there is where my problem resides, because i am not being able to find anywhere how to get all that info in order to build my table headers so then i can scrape the rest of the table.

Anyone knows a way of doing it? been trying for 4 days without success before posting here.
Then i tried to get all the spans using this code:
thead = soup.thead
Theaders = thead.find_all('span')
print(Theaders)
Output:
[<span title="Appearances"> </span>, <span title="Goals"> </span>, <span title="Assists"> </span>, <span title="Yellow cards"> </span>, <span title="Second yellow cards"> </span>, <span title="Red cards"> </span>, <span title="Substitutions on"> </span>, <span title="Substitutions off"> </span>, <span title="Minutes played"> </span>]
Getting close i thought as i could see all the info i needed was there. But then i hit the wall, i can get one span title but not all in a list:
thead = soup.thead Theaders = thead.find('span')['title'] print(Theaders)
Output: Appearances
thead = soup.thead
Theaders = thead.find_all('span')['title']
print(Theaders)
Output:
---> 23 Theaders = thead.find_all('span')['title']
24 print(Theaders)
TypeError: list indices must be integers or slices, not str
and even then i will run into the problem of it not being in the same order as it was on the original table.
Maybe i am just being dumb but any help would be much aprecciated
CodePudding user response:
you can get what's missing from
>>> [span.get_attribute_list("title")[0] for span in thead.find_all('span')]
['Appearances',
'Goals',
'Assists',
'Yellow cards',
'Second yellow cards',
'Red cards',
'Substitutions on',
'Substitutions off',
'Minutes played']
And then manually link those results with what you previously had at headers_tabela.
However, for consistency, I recommend fetching them one by one:
def anchor_span(th):
try:
return th.a.span.get_attribute_list("title")[0]
except Exception as exc:
#print(exc)
return False
def th_text(th):
try:
return th.text
except Exception as exc:
print(exc)
return False
def anchor_text(th):
try:
ch = th.a.children
assert len([*ch])==1
return th.a.text
except Exception as exc:
#print(exc)
return False
def get_col_names(soup):
colnames = []
for colnum, th in enumerate(soup.thead.tr.children):
if isinstance (th, bs4.element.NavigableString):
continue
title = anchor_span(th)
if not title:
title = anchor_text(th)
if not title:
title = th_text(th)
if not title:
raise NotImplementedError
colnames.append(title)
table_MN = pd.read_html(response.content, flavor='html5lib')
data = table_MN[1].iloc[:,:15]
data.columns = get_col_names(soup)
CodePudding user response:
from bs4 import BeautifulSoup
import requests
url = 'https://www.transfermarkt.co.uk/manchester-united-fc/leistungsdaten/verein/985/reldata/&2022/plus/1'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.content, 'lxml')
html_headers = soup.find_all('a', {'class': 'sort-link'})
headers_list = []
for i in html_headers:
if i.find('span') == None:
headers_list.append(i.get_text())
else:
headers_list.append(i.find('span')['title'])
print(headers_list)