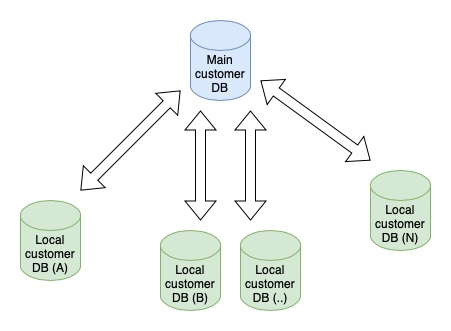
The central database(blue) will hold all customer data of the project.
The local databases(green) will be deployed at the physical locations containing a copy of the customer databases. Multiple stores can be deployed across geographical areas (A, B,...N) to allow customers to register and make purchases.
When a customer is registered at a local store, it should be updated in the central database with the purchase history. When a customer is registered, his purchase history should also be available in other stores.
For example, in the morning, a customer can purchase from store A, and afterward, customers should be able to purchase from store B/C or any other without registering again.
MySQL will be used as the database.
Advise is expected,
- Is there a database architecture or pattern that we can achieve this?
- What's the best approach to implement this?
Referred: Database Architecture, Central and/vs Localized Server
CodePudding user response:
There are three popular replication algorithms according:
- single-leader. When just there is one leader node
- multi-leader. When there are many leader nodes
- leadeless. When there is no leader node
Read more about these algorithms in "Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems" by Martin Kleppmann. As a quick overview, you can read this article "Database replication — an overview".
When a customer is registered at a local store, it should be updated in the central database with the purchase history. When a customer is registered, his purchase history should also be available in other stores.
It looks like you need to use master-master replication or multi-master or multi-leader replication. As wiki says:
Multi-master replication is a method of database replication which allows data to be stored by a group of computers, and updated by any member of the group. All members are responsive to client data queries. The multi-master replication system is responsible for propagating the data modifications made by each member to the rest of the group and resolving any conflicts that might arise between concurrent changes made by different members.
And MySql supports this:
MySQL Group Replication is a MySQL Server plugin that enables you to create elastic, highly-available, fault-tolerant replication topologies.
Groups can operate in a single-primary mode with automatic primary election, where only one server accepts updates at a time. Alternatively, for more advanced users, groups can be deployed in multi-primary mode, where all servers can accept updates, even if they are issued concurrently
I highly recommend you to read chapter "Replication" of book "Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems" by Martin Kleppmann
CodePudding user response:
Short Answer: Nothing standard within MySQL.
Long Answer: It is a tough problem because of network outages, temporary server outages, etc.
Partial solutions:
The "right" answer is to have every "customer" not have its own database, but instead, do all reads and writes on the "Main computer".
To have only local data on each "customer" db (which would be a Primary), the Main could be a Replica receiving updates from each customer. But this says that the only complete copy is on Main.
To have each customer have all the data, you must write to main (Primary) and read locally (Replica).