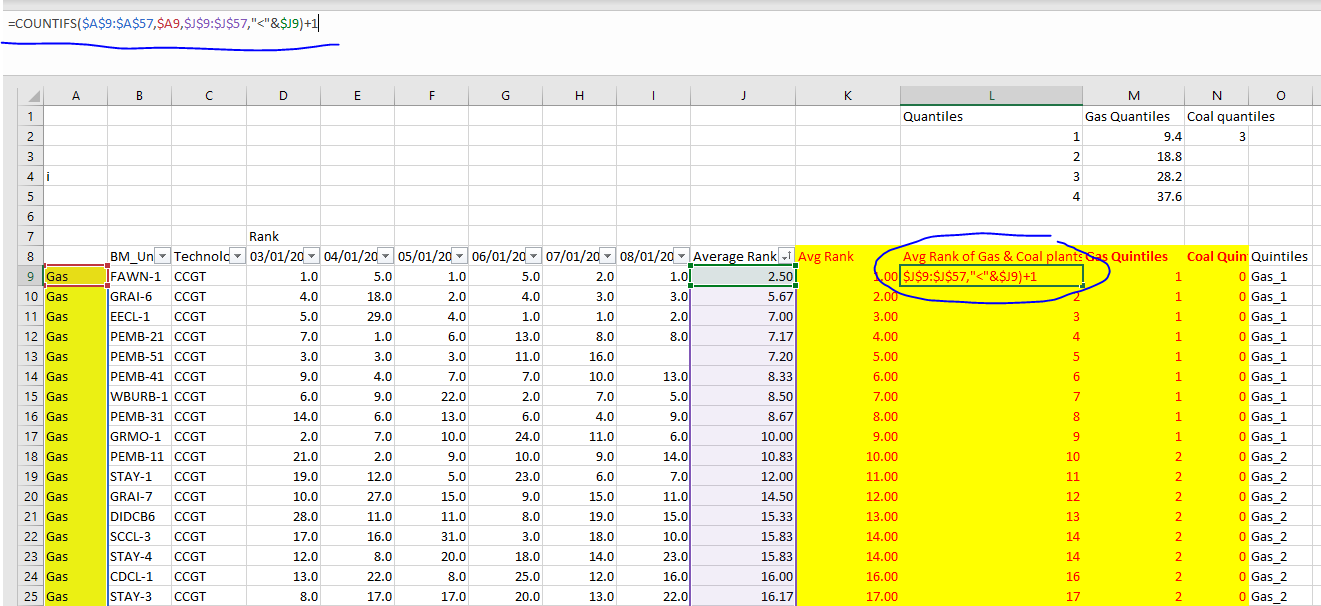
I am trying to replicate countifs in excel to get a rank between two unique values that are listed in my dataframe. I have attached the expected output calculated in excel using countif and let/rank functions.
I am trying to generate "average rank of gas and coal plants" that takes the number from the "average rank column" and then ranks the two unique types from technology (CCGT or COAL) into two new ranks (Gas or Coal) so then I can get the relavant quantiles for this. In case you are wondering why I would need to do this seeing as there are only two coal plants, well when I run this model on a larger dataset it will be useful to know how to do this in code and not manually on my dataset.
Ideally the output will return two ranks 1-47 for all units with technology == CCGT and 1-2 for all units with technology == COAL.
| This is the column I am looking to make | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unit ID | Technology | 03/01/2022 | 04/01/2022 | 05/01/2022 | 06/01/2022 | 07/01/2022 | 08/01/2022 | Average Rank | Unit Rank | Avg Rank of Gas & Coal plants | Gas Quintiles | Coal Quintiles | Quintiles |
| FAWN-1 | CCGT | 1.0 | 5.0 | 1.0 | 5.0 | 2.0 | 1.0 | 2.5 | 1 | 1 | 1 | 0 | Gas_1 |
| GRAI-6 | CCGT | 4.0 | 18.0 | 2.0 | 4.0 | 3.0 | 3.0 | 5.7 | 2 | 2 | 1 | 0 | Gas_1 |
| EECL-1 | CCGT | 5.0 | 29.0 | 4.0 | 1.0 | 1.0 | 2.0 | 7.0 | 3 | 3 | 1 | 0 | Gas_1 |
| PEMB-21 | CCGT | 7.0 | 1.0 | 6.0 | 13.0 | 8.0 | 8.0 | 7.2 | 4 | 4 | 1 | 0 | Gas_1 |
| PEMB-51 | CCGT | 3.0 | 3.0 | 3.0 | 11.0 | 16.0 | 7.2 | 5 | 5 | 1 | 0 | Gas_1 | |
| PEMB-41 | CCGT | 9.0 | 4.0 | 7.0 | 7.0 | 10.0 | 13.0 | 8.3 | 6 | 6 | 1 | 0 | Gas_1 |
| WBURB-1 | CCGT | 6.0 | 9.0 | 22.0 | 2.0 | 7.0 | 5.0 | 8.5 | 7 | 7 | 1 | 0 | Gas_1 |
| PEMB-31 | CCGT | 14.0 | 6.0 | 13.0 | 6.0 | 4.0 | 9.0 | 8.7 | 8 | 8 | 1 | 0 | Gas_1 |
| GRMO-1 | CCGT | 2.0 | 7.0 | 10.0 | 24.0 | 11.0 | 6.0 | 10.0 | 9 | 9 | 1 | 0 | Gas_1 |
| PEMB-11 | CCGT | 21.0 | 2.0 | 9.0 | 10.0 | 9.0 | 14.0 | 10.8 | 10 | 10 | 2 | 0 | Gas_2 |
| STAY-1 | CCGT | 19.0 | 12.0 | 5.0 | 23.0 | 6.0 | 7.0 | 12.0 | 11 | 11 | 2 | 0 | Gas_2 |
| GRAI-7 | CCGT | 10.0 | 27.0 | 15.0 | 9.0 | 15.0 | 11.0 | 14.5 | 12 | 12 | 2 | 0 | Gas_2 |
| DIDCB6 | CCGT | 28.0 | 11.0 | 11.0 | 8.0 | 19.0 | 15.0 | 15.3 | 13 | 13 | 2 | 0 | Gas_2 |
| SCCL-3 | CCGT | 17.0 | 16.0 | 31.0 | 3.0 | 18.0 | 10.0 | 15.8 | 14 | 14 | 2 | 0 | Gas_2 |
| STAY-4 | CCGT | 12.0 | 8.0 | 20.0 | 18.0 | 14.0 | 23.0 | 15.8 | 14 | 14 | 2 | 0 | Gas_2 |
| CDCL-1 | CCGT | 13.0 | 22.0 | 8.0 | 25.0 | 12.0 | 16.0 | 16.0 | 16 | 16 | 2 | 0 | Gas_2 |
| STAY-3 | CCGT | 8.0 | 17.0 | 17.0 | 20.0 | 13.0 | 22.0 | 16.2 | 17 | 17 | 2 | 0 | Gas_2 |
| MRWD-1 | CCGT | 19.0 | 26.0 | 5.0 | 19.0 | 17.3 | 18 | 18 | 2 | 0 | Gas_2 | ||
| WBURB-3 | CCGT | 24.0 | 14.0 | 17.0 | 17.0 | 18.0 | 19 | 19 | 3 | 0 | Gas_3 | ||
| WBURB-2 | CCGT | 14.0 | 21.0 | 12.0 | 31.0 | 18.0 | 19.2 | 20 | 20 | 3 | 0 | Gas_3 | |
| GYAR-1 | CCGT | 26.0 | 14.0 | 17.0 | 20.0 | 21.0 | 19.6 | 21 | 21 | 3 | 0 | Gas_3 | |
| STAY-2 | CCGT | 18.0 | 20.0 | 18.0 | 21.0 | 24.0 | 20.0 | 20.2 | 22 | 22 | 3 | 0 | Gas_3 |
| KLYN-A-1 | CCGT | 24.0 | 12.0 | 19.0 | 27.0 | 20.5 | 23 | 23 | 3 | 0 | Gas_3 | ||
| SHOS-1 | CCGT | 16.0 | 15.0 | 28.0 | 15.0 | 29.0 | 27.0 | 21.7 | 24 | 24 | 3 | 0 | Gas_3 |
| DIDCB5 | CCGT | 10.0 | 35.0 | 22.0 | 22.3 | 25 | 25 | 3 | 0 | Gas_3 | |||
| CARR-1 | CCGT | 33.0 | 26.0 | 27.0 | 22.0 | 4.0 | 22.4 | 26 | 26 | 3 | 0 | Gas_3 | |
| LAGA-1 | CCGT | 15.0 | 13.0 | 29.0 | 32.0 | 23.0 | 24.0 | 22.7 | 27 | 27 | 3 | 0 | Gas_3 |
| CARR-2 | CCGT | 24.0 | 25.0 | 27.0 | 29.0 | 21.0 | 12.0 | 23.0 | 28 | 28 | 3 | 0 | Gas_3 |
| GRAI-8 | CCGT | 11.0 | 28.0 | 36.0 | 16.0 | 26.0 | 25.0 | 23.7 | 29 | 29 | 4 | 0 | Gas_4 |
| SCCL-2 | CCGT | 29.0 | 16.0 | 28.0 | 25.0 | 24.5 | 30 | 30 | 4 | 0 | Gas_4 | ||
| LBAR-1 | CCGT | 19.0 | 25.0 | 31.0 | 28.0 | 25.8 | 31 | 31 | 4 | 0 | Gas_4 | ||
| CNQPS-2 | CCGT | 20.0 | 32.0 | 32.0 | 26.0 | 27.5 | 32 | 32 | 4 | 0 | Gas_4 | ||
| SPLN-1 | CCGT | 23.0 | 30.0 | 30.0 | 27.7 | 33 | 33 | 4 | 0 | Gas_4 | |||
| DAMC-1 | CCGT | 23.0 | 21.0 | 38.0 | 34.0 | 29.0 | 34 | 34 | 4 | 0 | Gas_4 | ||
| KEAD-2 | CCGT | 30.0 | 30.0 | 35 | 35 | 4 | 0 | Gas_4 | |||||
| SHBA-1 | CCGT | 26.0 | 23.0 | 35.0 | 37.0 | 30.3 | 36 | 36 | 4 | 0 | Gas_4 | ||
| HUMR-1 | CCGT | 22.0 | 30.0 | 37.0 | 37.0 | 33.0 | 28.0 | 31.2 | 37 | 37 | 4 | 0 | Gas_4 |
| CNQPS-4 | CCGT | 27.0 | 33.0 | 35.0 | 30.0 | 31.3 | 38 | 38 | 5 | 0 | Gas_5 | ||
| CNQPS-1 | CCGT | 25.0 | 40.0 | 33.0 | 32.7 | 39 | 39 | 5 | 0 | Gas_5 | |||
| SEAB-1 | CCGT | 32.0 | 34.0 | 36.0 | 29.0 | 32.8 | 40 | 40 | 5 | 0 | Gas_5 | ||
| PETEM1 | CCGT | 35.0 | 35.0 | 41 | 41 | 5 | 0 | Gas_5 | |||||
| ROCK-1 | CCGT | 31.0 | 34.0 | 38.0 | 38.0 | 35.3 | 42 | 42 | 5 | 0 | Gas_5 | ||
| SEAB-2 | CCGT | 31.0 | 39.0 | 39.0 | 34.0 | 35.8 | 43 | 43 | 5 | 0 | Gas_5 | ||
| WBURB-43 | COAL | 32.0 | 37.0 | 40.0 | 39.0 | 31.0 | 35.8 | 44 | 1 | 0 | 1 | Coal_1 | |
| FDUNT-1 | CCGT | 36.0 | 36.0 | 45 | 44 | 5 | 0 | Gas_5 | |||||
| COSO-1 | CCGT | 30.0 | 42.0 | 36.0 | 36.0 | 45 | 44 | 5 | 0 | Gas_5 | |||
| WBURB-41 | COAL | 33.0 | 38.0 | 41.0 | 40.0 | 32.0 | 36.8 | 47 | 2 | 0 | 1 | Coal_1 | |
| FELL-1 | CCGT | 34.0 | 39.0 | 43.0 | 41.0 | 33.0 | 38.0 | 48 | 46 | 5 | 0 | Gas_5 | |
| KEAD-1 | CCGT | 43.0 | 43.0 | 49 | 47 | 5 | 0 | Gas_5 |
I have tried to do it the same way I got average rank, which is a rank of the average of inputs in the dataframe but it doesn't seem to work with additional conditions.
Thank you!!
CodePudding user response:
import pandas as pd
df = pd.read_csv("gas.csv")
display(df['Technology'].value_counts())
print('------')
display(df['Technology'].value_counts()[0]) # This is how you access count of CCGT
display(df['Technology'].value_counts()[1])
Output:
CCGT 47
COAL 2
Name: Technology, dtype: int64
------
47
2
By the way: pd.cut or pd.qcut can be used to calculate quantiles. You don't have to manually define what a quantile is.
Refer to the documentation and other websites:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.qcut.html
https://www.geeksforgeeks.org/how-to-use-pandas-cut-and-qcut/
There are many methods you can pass to rank. Refer to documentation:
df['rank'] = df.groupby("Technology")["Average Rank"].rank(method = "dense", ascending = True)
df
method{‘average’, ‘min’, ‘max’, ‘first’, ‘dense’}, default ‘average’
How to rank the group of records that have the same value (i.e. ties):
average: average rank of the group
min: lowest rank in the group
max: highest rank in the group
first: ranks assigned in order they appear in the array
dense: like ‘min’, but rank always increases by 1 between groups.