This is a simple python language code, and I want to know the address of variable a:
if __name__ == '__main__':
a = 2
print(a)
print(id(2))
print(id(a))
The output is:
2
140704200824512
140704200824512
But I don't think the address of variable a is 140704200824512. I think 140704200824512 is the address of data 2.
As shown below, what is the value of the red question mark?
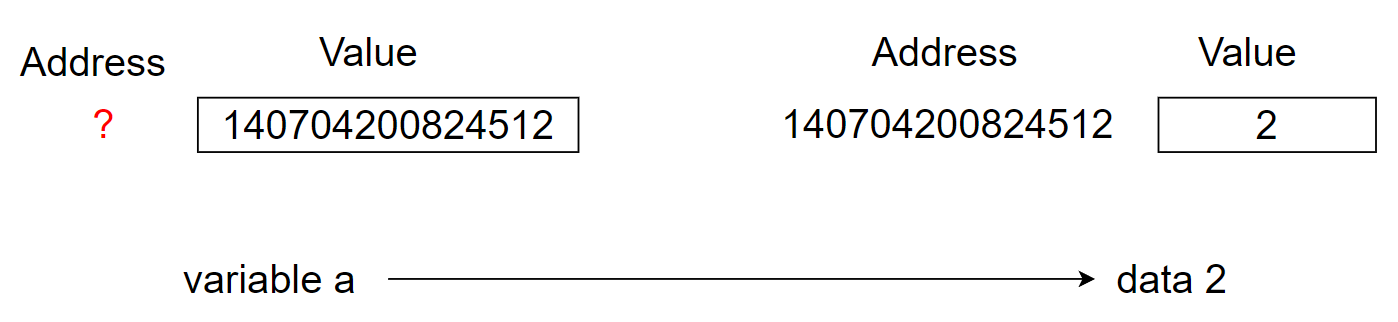
Maybe the figure above is totally wrong because some documentation says the variables actually don't exist in python. They are just entries in namespace. But I still don't understand the internal principle.
In C programming language, it is easy to understand the relationship between variable and data, but in python programming language, it is hard.
This is a simple C language code:
#include <stdio.h>
int main(){
int a = 2;
printf("%d\n",a);
printf("%x\n",&a);
}
The output is:
2
60fe1c
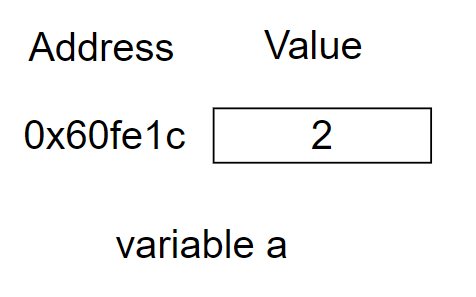
The relationship between variable a and data 2 is simple: a stores 2. Just as the following:
Can someone answer my question?
CodePudding user response:
"CPython implementation detail: This is the address of the object in memory." - https://docs.python.org/3/library/functions.html#id
The reason why you are seeing id(a) == id(2) is because Python uses something reffered to as Small Integer Caching - integers in range [-5, 256] are cached, so usually most of the variables referring to specific integer in that range point to the very same cached integer - https://stackoverflow.com/a/15172182/9296093; it also performs some other memory optimization, so you might observe similiar behaviour for higher numbers.
Same numbers can, but do not need to have the same id:
a = 10000
a = 10
b = 10
for i in range(4):
a *= 10
b *= 10
print(f"{id(a) = }, {a = }")
print(f"{id(b) = }, {b = }")
Output:
id(a) = 140713648512904, a = 100
id(b) = 140713648512904, b = 100
id(a) = 2498426551376, a = 1000
id(b) = 2498426551664, b = 1000
id(a) = 2498426551728, a = 10000
id(b) = 2498426551376, b = 10000
id(a) = 2498426551664, a = 100000
id(b) = 2498426551728, b = 100000
CodePudding user response:
As the other answer says, there is small integer caching happening, but also some other memory optimization.
Below is an example, where you can see compilation time optimization, which behaves differently if running through a REPL or as a a script:
# Left value is if run in **script**
# Right value is if run in **REPL** or **IPython**
a = 200
b = 200
print(a is b) # True | True
a = 300
b = 300
print(a is b) # True | *False*
a, b = 300, 300
print(a is b) # True | True
a = ((10, 20), (30, 40))
b = ((10, 20), (30, 40))
print(a is b) # True | *False*
a, b = ((10, 20), (30, 40)), ((10, 20), (30, 40))
print(a is b) # True | True