I am trying to write few regex . I am testing my regex on below link
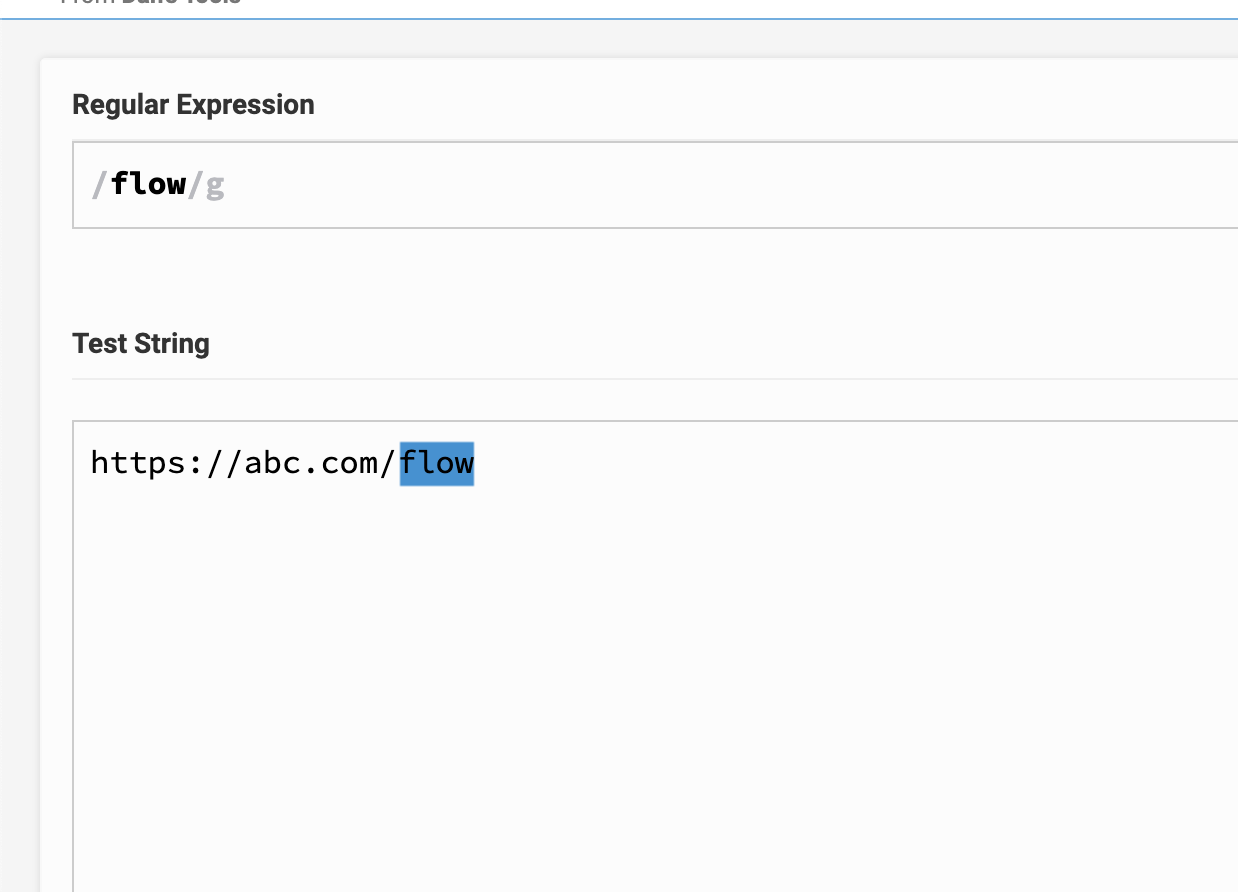
case 2
- /_next/.*
Testing string: 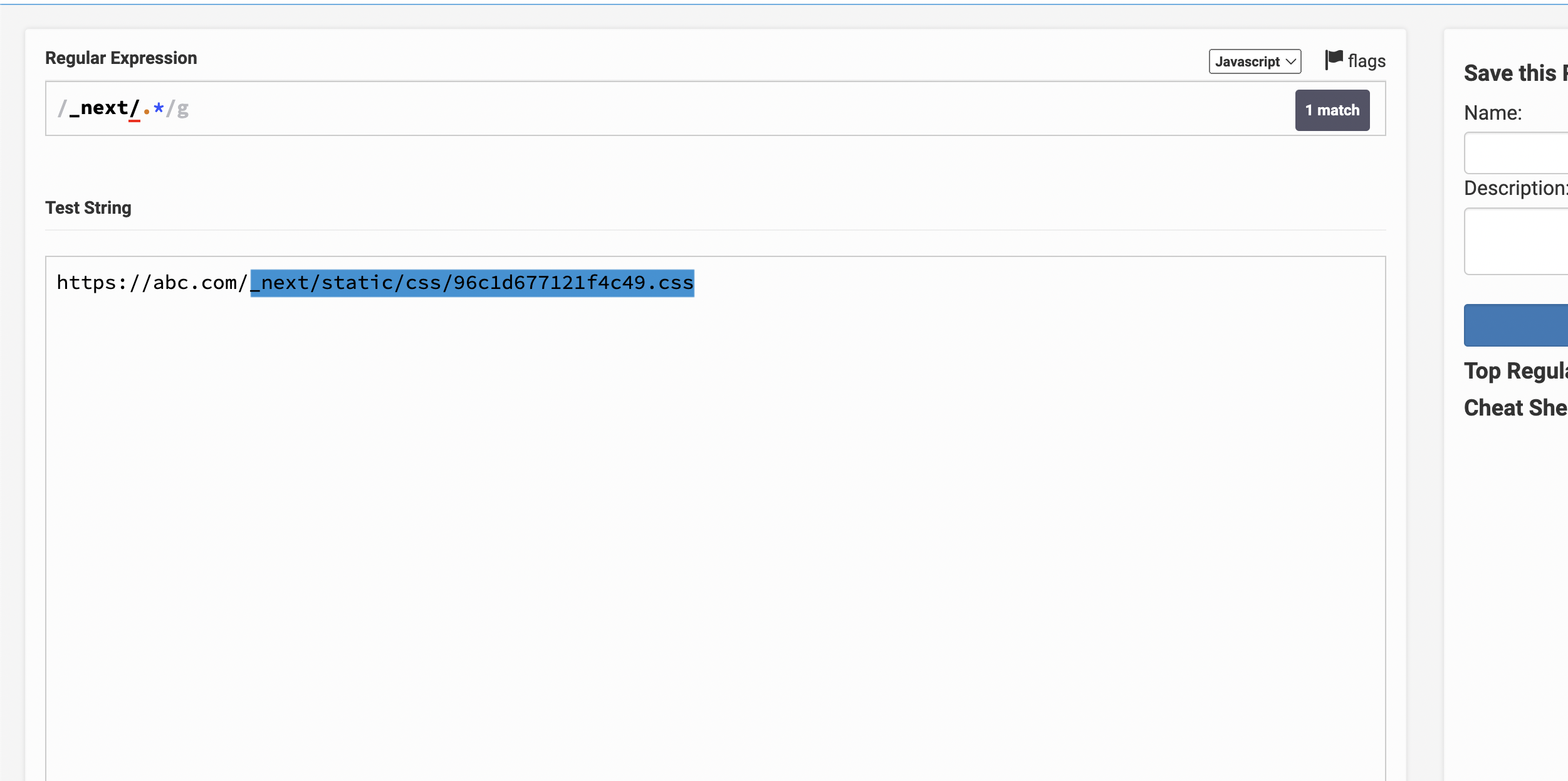
Case 3:
- regex: /(. .(css|js))
Testing string:
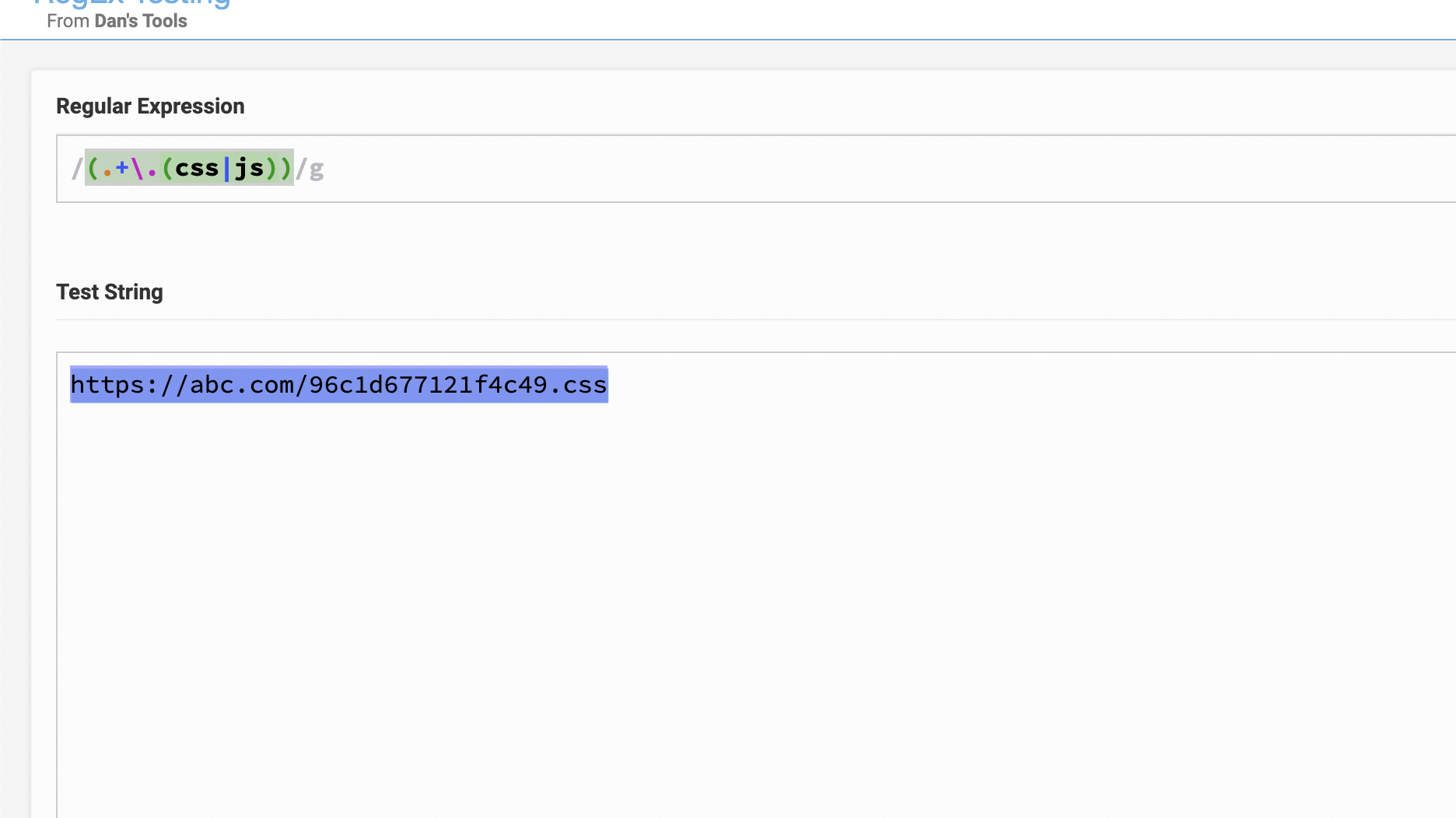
Expected output : ONLY select "96c1d677121f4c49.css" NOT domain
any way to fix this bug ?
CodePudding user response:
You can use
[^\/#?] \.(?:css|js)(?![^\/?#])Details:
[^\/#?]- one or more chars other than/,?and#\.- a literal dot(?:css|js)-cssorjs(?![^\/?#])- a negative lookahead that requires end of string or a/,?or#char immediately to the right of the current location.
See the regex demo.
CodePudding user response:
You should try to use javascript built in Url object tooling to extract everything you need including pathname (/flow), or parameters. See more here : https://dmitripavlutin.com/parse-url-javascript/
Hope this helps you find a way to properly parse your urls
CodePudding user response:
There's a built-in URL API to help you parse URLs:
const urls = [ "https://example.com/flow", "https://example.com/_next/static/css/96c1d677121f4c49.css", "https://example.com/96c1d677121f4c49.css", ]; for (const string of urls) { const url = new URL(string); // slice to get rid of leading '/' console.log(url.pathname.slice(1)); }CodePudding user response:
You can use the positive lookbehind technique, to search for the slash before the file
(?<=\/)\w*\.(css|js).(?<=\/)check for a slash before the target text.\w*any number of word character\.for dot(css|js)for css or js extension.