I have a large excel file containing stock data loaded from and sorted from an API. Below is a sample of dummy data that is applicable towards solving this problem:
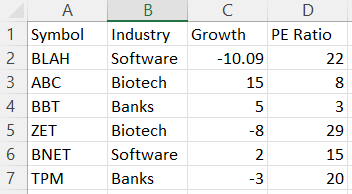
I would like to create a function that Scores Stocks grouped by their Industry. For this sample I would like to score a stock a 5 if its ['Growth'] value is less than its groups mean Growth (quantile, percentile) in Growth and a 10 if above the groups mean growth. The scores of all values in a column should be returned in a list
Current Unfinished Code:
import numpy as np
import pandas as pd
data = pd.DataFrame(pd.read_excel('dummydata.xlsx')
Desired input:
data['Growth'].apply(score) # Scores stock
Desired Output:
[5, 10, 10, 5, 10, 5]
If I can create a function for this sample then I will be able to make similar ones for different columns with slightly different conditions and aggregates (like percentile or quantile) that affect the score. I'd say the main problem here is accessing these grouped values and comparing them.
CodePudding user response:
I don't think it's possible to convert from a Series to a list in the apply call. I may be wrong on that but if the desired output was changed slightly to
data['Growth'].apply(score).tolist()
then you can use a lambda function to do this.
score = lambda x: 5 if x < growth.mean() else 10
data['Growth'].apply(score).tolist() # outputs [5, 10, 10, 5, 10, 5]