I want to collect GitHub users' monthly contributions from 2004 until now as shown in the picture. 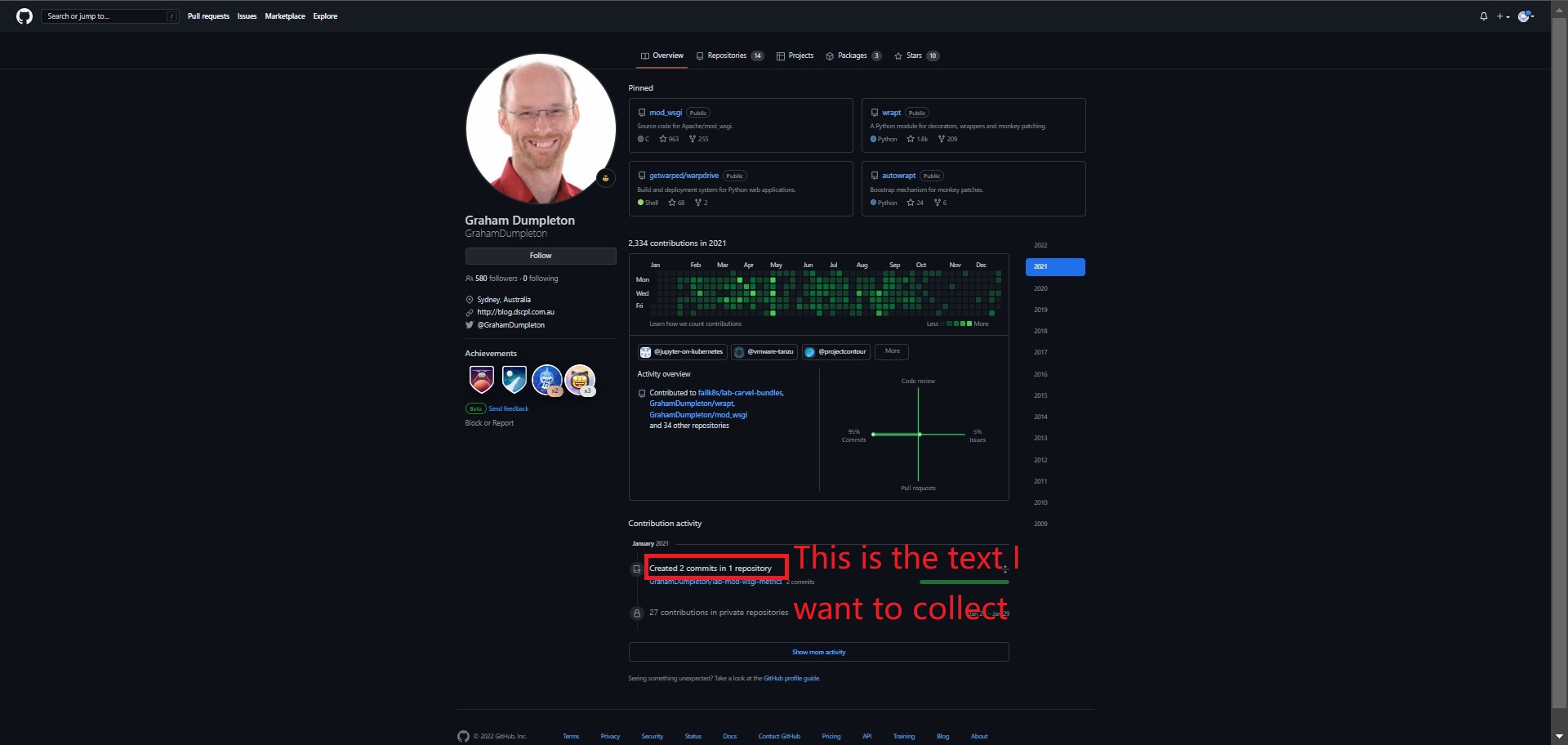 And output the monthly data into csv file with corresponding month columns (e.g., 2022_10). The Xpath of these texts is:
And output the monthly data into csv file with corresponding month columns (e.g., 2022_10). The Xpath of these texts is:
#//*[@id="js-contribution-activity"]/div/div/div/div/details/summary/span[1]
This is what my csv file (df1) looks like:
| LinkedIn Website | GitHub Website | user | |
|---|---|---|---|
| 0 | https://www.linkedin.com/in/chad-roberts-b86699/ | https://github.com/crobby | crobby |
| 1 | https://www.linkedin.com/in/grahamdumpleton/ | https://github.com/GrahamDumpleton | GrahamDumpleton |
Here is my best try so far:
for index, row in df1.iterrows():
try:
user = row['user']
except:
pass
for y in range(2004, 2023):
for m in range(1, 13):
try:
current_url = f'https://github.com/{user}?tab=overview&from={y}-{m}-01&to={y}-{m}-31'
print(current_url)
driver.get(current_url)
time.sleep(0.1)
contribution = driver.findElement(webdriver.By.xpath("//*[@id='js-contribution-activity']/div/div/div/div/details/summary/span[1]")).getText();
df1.loc[index, f'{str(y)}_{str(m)}'] = contribution
except:
pass
print(df1)
df1.to_csv('C:/Users/fredr/Desktop/output today.csv')
I cannot figure out why there is no output. Thanks for your help.
CodePudding user response:
You need to use WebDriverWait expected_conditions explicit waits.
I see there are multiple contribution fields there, so you need to collect all those elements as a list and then to iterate over the list extracting each element text.
You need to improve your locators, they should be short and clear as possible.
Also you mixed in your code Java and Python. getText() and ; are from Java...
Try this:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
driver.get(current_url)
contributions = wait.until(EC.visibility_of_all_elements_located((By.XPATH, "//*[@id='js-contribution-activity']//summary/span[1]")))
for contribution in contributions:
print(contribution.text)
CodePudding user response:
I haven't tried it with selenium but with just requests and lxml this xpath expression
//div[@]//details[@]/summary/span[1]
seems to work.