I am tasked with extracting unique values from record, from a previously used 'Notes' Nvarchar(max) field.
CREATE TABLE LWArchive (
Number int,
Notes varchar(MAX))
INSERT INTO LWArchive(Number,Notes)
VALUES(1,'OGC 503360 / 503361 M303834 M303838 M303835 M303836 M303837 M303839 M303840 M303841 303842'),
(2,'OGC = Q.6773'),
(3,'DEED REF = 0001'),
(4,'OGC 50336 / 50336 M30383 M03038 M30383 M30383 M30383 M00303 M303840 M303841 M303842')
select
a.Number,
s.value
from LWArchive a
CROSS APPLY STRING_SPLIT(a.notes, N' ') s
The notes field contains multiple barcodes, which are all in a space delimited format.
E.G. 'M000001 M000002 M000003'
I have attempted to split the 'Notes' column using the query below:
select
a.ID,
s.value
from Archive a
CROSS APPLY STRING_SPLIT(a.notes, N' ') s
Unfortuntely, while some have worked correctly, the split results are inconsistant. With a number of the barcodes remaining unaffected within the space delimited results. Example Below:

When the string isn't sourced from a column & entered manually into the function. It functions as expected. Example Below:
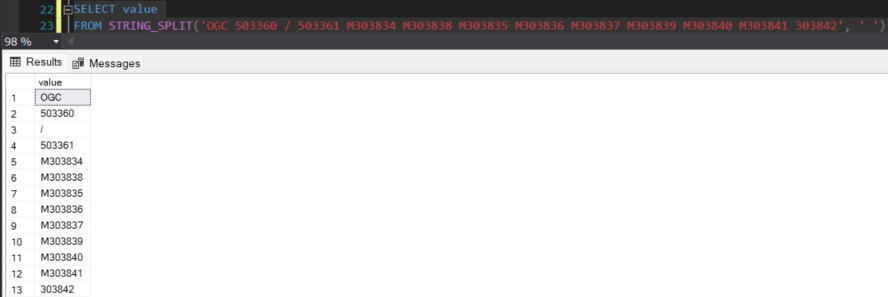
I am using SQL server 2019, however as this is legacy data. I've had to convert the database from compatibility 110 to 130 in order to access the String_Split function.
CodePudding user response:
As suggested in the comments you are likely finding an instance where the character is not a white space, but some other character.
DECLARE @string NVARCHAR(MAX) = 'M000001 M000002 M000003'
SELECT *, @string
FROM STRING_SPLIT(@string,' ')
value (No column name)
------------------------
M000001 M000001 M000002 M000003
M000002 M000001 M000002 M000003
M000003 M000001 M000002 M000003
This splits as expected. We end up with 3 rows each with one of the delimited values. If we change one of those white spaces for a tab:
SET @string = 'M000001 M000002 M000003'
SELECT *, @string
FROM STRING_SPLIT(@string,' ')
value (No column name)
--------------------------------
M000001 M000001 M000002 M000003
M000002 M000003 M000001 M000002 M000003
We can reproduce what you're seeing.
When I've faced similar problems I've found this technique to be useful:
;WITH cte AS (
SELECT @string AS completeString, ASCII(LEFT(@string, 1)) AS asciiCode, LEFT(@string, 1) AS this, RIGHT(@string, LEN(@string)-1) AS that, 1 AS charIndex
UNION ALL
SELECT completeString, ASCII(LEFT(that,1)), LEFT(that,1), RIGHT(that,LEN(that)-1), charIndex 1
FROM cte
WHERE that <> ''
)
SELECT *
FROM cte
This produces a result set for each character/glyph in the string and it's ASCII code.
completeString asciiCode this that charIndex
---------------------------------------------------------------------------------
M000001 M000002 M000003 77 M 000001 M000002 M000003 1
M000001 M000002 M000003 48 0 00001 M000002 M000003 2
M000001 M000002 M000003 48 0 0001 M000002 M000003 3
M000001 M000002 M000003 48 0 001 M000002 M000003 4
M000001 M000002 M000003 48 0 01 M000002 M000003 5
M000001 M000002 M000003 48 0 1 M000002 M000003 6
M000001 M000002 M000003 49 1 M000002 M000003 7
M000001 M000002 M000003 32 M000002 M000003 8
M000001 M000002 M000003 77 M 000002 M000003 9
M000001 M000002 M000003 48 0 00002 M000003 10
M000001 M000002 M000003 48 0 0002 M000003 11
M000001 M000002 M000003 48 0 002 M000003 12
M000001 M000002 M000003 48 0 02 M000003 13
M000001 M000002 M000003 48 0 2 M000003 14
M000001 M000002 M000003 50 2 M000003 15
M000001 M000002 M000003 9** M000003 16**
M000001 M000002 M000003 77 M 000003 17
M000001 M000002 M000003 48 0 00003 18
M000001 M000002 M000003 48 0 0003 19
M000001 M000002 M000003 48 0 003 20
M000001 M000002 M000003 48 0 03 21
M000001 M000002 M000003 48 0 3 22
M000001 M000002 M000003 51 3 23
Now we can clearly see that character 16 is actually a tab (CHAR(9)) not a white space (CHAR(32)).