I am currently working on a web scraping company logos with clearbit API. Like below(see code)
import pandas as pd
from selenium import webdriver
from bs4 import BeautifulSoup
data = {'name': ['tcs', 'orange', 'linkedin'],
'domain': ["tcs.com",
"orange.com",
"linkedin.com"]}
df = pd.DataFrame(data)
driver = webdriver.Chrome(r"chromedriver.exe")
for i in df['domain']:
driver.get("https://logo.clearbit.com/" str(i))
clear_api_html = BeautifulSoup(driver.page_source, 'html.parser')
clear_logo_access = clear_api_html.find_all('img')
output_dict = {'Logo': clear_logo_access, 'Website': i}
print(output_dict)
And I am having the output like below
driver = webdriver.Chrome(r"chromedriver.exe")
{'Logo': [<img src="https://logo.clearbit.com/tcs.com" style="display: block;-webkit-user-select: none;margin: auto;background-color: hsl(0, 0%, 90%);transition: background-color 300ms;"/>], 'Website': 'tcs.com'}
{'Logo': [<img src="https://logo.clearbit.com/orange.com" style="display: block;-webkit-user-select: none;margin: auto;background-color: hsl(0, 0%, 90%);transition: background-color 300ms;"/>], 'Website': 'orange.com'}
{'Logo': [<img src="https://logo.clearbit.com/linkedin.com" style="display: block;-webkit-user-select: none;margin: auto;background-color: hsl(0, 0%, 90%);transition: background-color 300ms;"/>], 'Website': 'linkedin.com'}
In the dictionery format, however I wanted the output results to append it to the existing dataframe.
expected output:
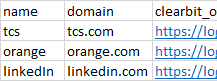
Please help me. Thanks in advance
CodePudding user response:
You are iterating over all domains. So if you append all urls to a list during the iteration, you can simply add a key to the dictionary.
logo_list = []
for i in df['domain']:
driver.get("https://logo.clearbit.com/" str(i))
clear_api_html = BeautifulSoup(driver.page_source, 'html.parser')
clear_logo_access = clear_api_html.find_all('img')
logo_list.append(clear_logo_access}
data['Logo'] = logo_list
Does that answer your question?