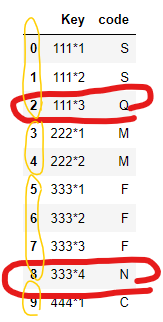
I have a dataframe shown below:
I would like to count how many time the "code" column has a different character from the Key column group: Ex: in this example the first group has two S but one Q then will count one. The second group it does not have a different char. The third group has three F but one N then will count the total 2
The loop should look at the the Key column and count 1 if there is any different char, then calculate the total number of counts.
The result is a new datframe that has two rows ( inside the red line circles )
# initialize data of lists.
data = {'Key': ['111*1', '111*2','111*3', '222*1','222*2', '333*1','333*2', '333*3','333*4', '444*1'],
'code': ['S', 'S','Q', 'M','M', 'F','F', 'F','N', 'C']}
# Create DataFrame
data = pd.DataFrame(data)
data
CodePudding user response:
It appears that you don't want duplicates... I recommend splitting the Key column then drop_duplicates.
df = {'Key': ['111*1', '111*2','111*3', '222*1','222*2', '333*1','333*2', '333*3','333*4', '444*1'],
'code': ['S', 'S','Q', 'M','M', 'F','F', 'F','N', 'C']}
# Create DataFrame
df = pd.DataFrame(df)
df[['Keya', 'Keyb']] = df['Key'].str.split('\\*', expand=True, regex=True)
print(df)
df.drop_duplicates(keep= False, subset=['code', 'Keya'], inplace=True)
df.drop(columns=['Keya', 'Keyb'], inplace=True)
print(df)
results
Key code
2 111*3 Q
8 333*4 N
9 444*1 C
CodePudding user response:
df = {'Key': ['111*1', '111*2','111*3', '222*1','222*2', '333*1','333*2', '333*3','333*4', '444*1'],
'code': ['S', 'S','Q', 'M','M', 'F','F', 'F','N', 'C']}
# Create DataFrame
df = pd.DataFrame(df)
df[['Keya', 'Keyb']] = df['Key'].str.split('\\*', expand=True, regex=True)
df = df.groupby(['Keya']).filter(lambda x: len(x)>1)
df.drop_duplicates(keep= False, subset=['code', 'Keya'], inplace=True)
df.drop(columns=['Keya', 'Keyb'], inplace=True)
print(df)