I need help with processing an unsorted dataset. Sry, if I am a complete noob. I never did anything like that before. So as you can see, each conversation is identified by a dialogueID which consists of multiple rows of "from" & "to", as well as text messages. I would like to concatenate the text messages from the same sender of a dialogueID to one column and from the receiver to another column. This way, I could have a new csv-file with just [dialogueID, sender, receiver].
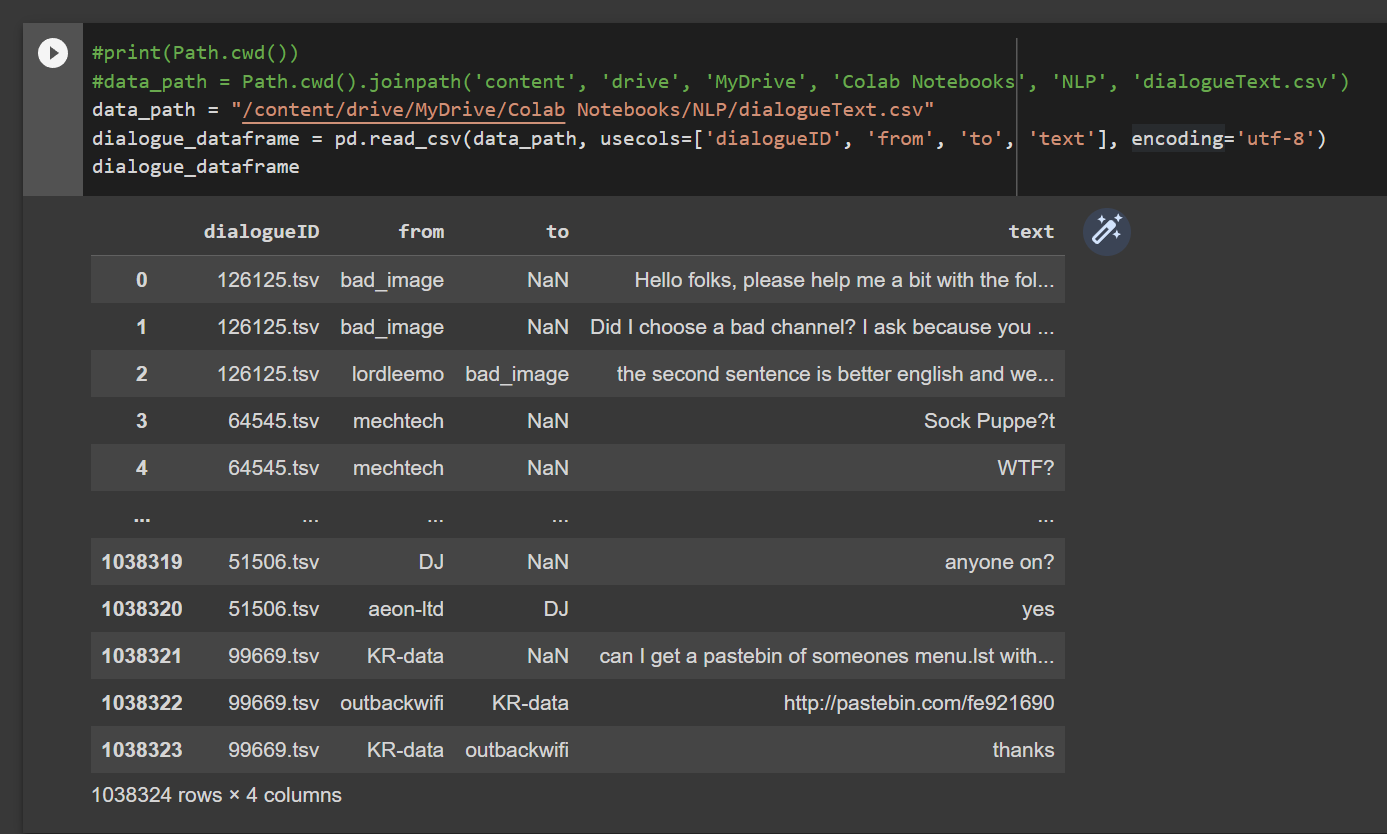 the new dataset should look like this
the new dataset should look like this
I watched multiple tutorials and really struggle to figure out how to do it. I read in this 9-year-old post that iterating through data frames are not a good idea. Could someone help me out with a code snippet or give me a hint on how to properly do it without overcomplicating things? I thought something like this pseudo code below, but the performance with 1 million rows is not great, right?
while !endOfFile
for dialogueID in range (0, 1038324)
if dialogueID 1 == dialogueID and toValue.isnull()
concatenate textFromPrevRow " " textFromCurrentRow
add new string to table column sender
else
add text to column receiver
CodePudding user response:
Not quite sure I understood what you try to achieve, but maybe this will give some insights. Maybe write a couple of rows of the table you expect to get, for better clarification
CodePudding user response:
While the exact structure of the data (and thus your task) is not completely clear, maybe DataFrame.apply or rather DataFrame.aggregate can help you speed things up. Also, I would aggregate into either a dictionary or dataframe indexed by dialogue id. This way you can easily check if a given dialogue / sender already exists.