The phenomenon that I am not able to understand is how pandas is able to join two dataframes using the equal operation as in the following code:
import pandas as pd
import numpy as np
from IPython.display import display
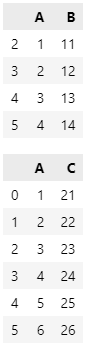
df1 = pd.DataFrame({"A": np.arange(1, 5), "B": np.arange(11, 15)})
df1.index = (np.arange(1, 5) 1).tolist()
df2 = pd.DataFrame({"A": np.arange(1, 7), "C": np.arange(21, 27)})
display(df1)
display(df2)
df1[["C"]] = df2[["C"]]
display(df1)
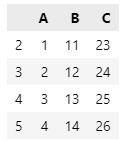
I cannot understand how merging happened in this case.
I would appreciate it if someone can guide me toward the original documentation and provide some further explanation for this behavior.
Many thanks in advance!
CodePudding user response:
This is a basic feature of pandas, automatic index alignment. This is indeed one of the core features which distinguishes it from just numpy (on top of which it is built). Briefly, at index 2 of df1, the new column will get the value 23 (from index 2 in df2['C']). At index 3, the new column will get the value 24 from index 3 in df['C'], etc etc –
So, one way you can think of this is that there is no need to do manual index alignment, i.e.:
df1['C'] = df2.loc[df1.index, 'C']
Because
df1['C'] = df2['C']
does that alignment automatically for you (we could envision an API where this wasn't the case, and the above, for example, throws an error because df2 is bigger than df1 so it would be ambiguous what you want to do without automatic alignment)
See the introductory tutorial:
Fundamentally, data alignment is intrinsic. The link between labels and data will not be broken unless done so explicitly by you.
Some more useful parts of the tutorial: