I have the following the following columns,
column_1 = ["Northern Rockies, British Columbia [9A87]", "Northwest Territories [2H89]", "Canada [00052A]", "Division No. 1, Newfoundland and Labrador [52A]"]
column_2 = ["aa", "bb", "cc", "dd"]
column_3 = [4, 4.5, 23, 1]
zipped = list(zip(column_1 , column_2, column_3))
df = pd.DataFrame(zipped, columns=['column_1' , 'column_2', 'column_3'])
I want to extract the text between the square brackets from the first column as a separate column. Below is the output I am looking for,
column_1 = ["Northern Rockies, British Columbia", "Northwest Territories", "Canada", "Division No. 1, Newfoundland and Labrador"]
column_2 = ["aa", "bb", "cc", "dd"]
column_3 = [4, 4.5, 23, 1]
column_4 = ["9A87", "2H89", "00052A", "52A"]
zipped = list(zip(column_1 , column_2, column_3, column_4))
df = pd.DataFrame(zipped, columns=['column_1' , 'column_2', 'column_3', 'column_4'])
I am using square bracket here but I think the solution should apply to any type of bracket.
CodePudding user response:
I would use str.extract and str.repalce here:
df["column_4"] = df["column_1"].str.extract(r'\[(.*?)\]')
df["column_1"] = df["column_1"].str.replace(r'\s*\[.*?\]$', '', regex=True)
CodePudding user response:
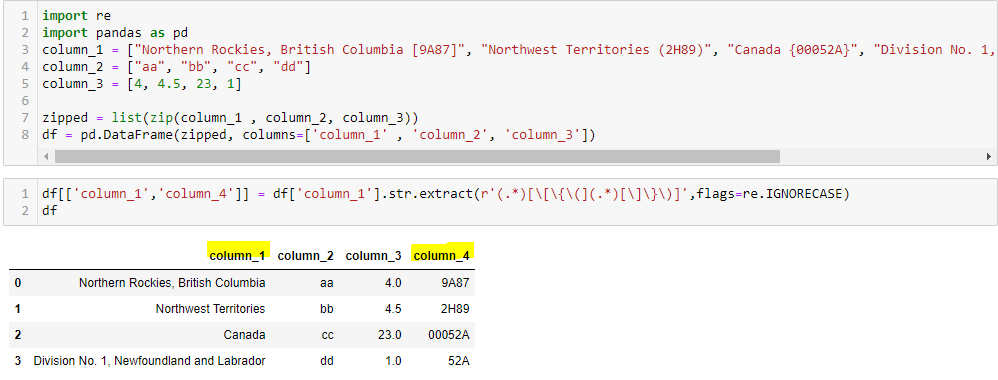
Hello, Salahuddin! From the column_1, I assumed that square brackets or any kind of brackets come always after the text. eg. Northern Rockies, British Columbia [9A87]
df[['column_1','column_4']] = df['column_1'].str.extract(r'(.*)[\[\{\(](.*)[\]\}\)]',flags=re.IGNORECASE)
This will work for any kind of brackets like [], (), {}