I have a dataframe that has 100 columns. The columns have either a 1 (for yes) and 0 (for no) as seen below.
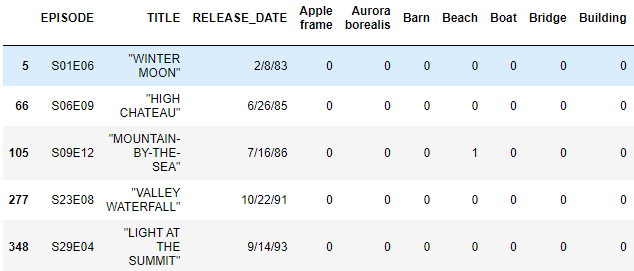
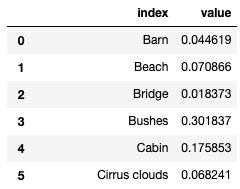
I'm trying to find out the percentage of each - such as "what percentage of the episodes have a barn?" or "what percentage of the episodes have a beach?" I think I'll need to iterate through the rows and put these in buckets, but I'm wondering how. The total number of episodes is 381, which I know I'll need to find the total percentage of each. The end product should look like this:
CodePudding user response:
is this what you mean?
df = pd.DataFrame([[1,1,0],[0,0,1],[1,0,1],[0,0,1]],
columns=['barn','beach','boat'])
>>> df
'''
barn beach boat
0 1 1 0
1 0 0 1
2 1 0 1
3 0 0 1
'''
>>> df.mean().reset_index(name='value')
'''
index value
0 barn 0.50
1 beach 0.25
2 boat 0.75