I have a dataframe which looks like:
df <- data.frame(col1 = c(2,3,6,1,8,4,8,2,4,5,7,4,2,7),col2 = c(rep(1,4),rep(2,3),rep(3,4),rep(4,3)))
Now I want a column rem_val which starts with a starting value 40 grouped by column col2, and subtracts the previous row from col1 from this value.
So the dataframe should look like:
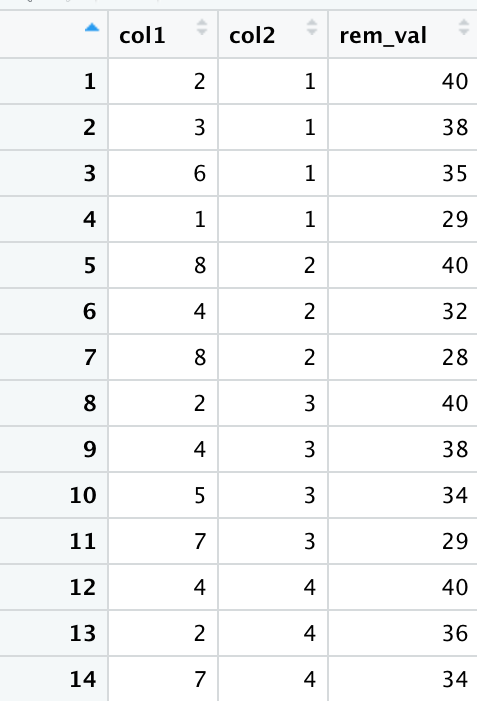
I thought of reverse cumulative frequency but I want to have a starting value which is defined by the user, like 40 here.
CodePudding user response:
library(dplyr)
df %>%
group_by(col2) %>%
mutate(rem_val = 40 - cumsum(lag(col1, default = 0))) %>%
ungroup()
CodePudding user response:
Here is another option.
library(tidyverse)
df |>
group_by(col2) |>
mutate(rem_val = Reduce("-", head(col1, n()-1), accumulate = TRUE, init = 40))
#> # A tibble: 14 x 3
#> # Groups: col2 [4]
#> col1 col2 rem_val
#> <dbl> <dbl> <dbl>
#> 1 2 1 40
#> 2 3 1 38
#> 3 6 1 35
#> 4 1 1 29
#> 5 8 2 40
#> 6 4 2 32
#> 7 8 2 28
#> 8 2 3 40
#> 9 4 3 38
#> 10 5 3 34
#> 11 7 3 29
#> 12 4 4 40
#> 13 2 4 36
#> 14 7 4 34