I have the data in the following format:
CodePudding user response:
Create a sample for demo.
import pandas as pd
import numpy as np
# create a dataframe with 100 rows random with column year random between 1950-2020
df = pd.DataFrame({'year': np.random.randint(1950, 2020, 100)})
df['revenue'] = np.random.randint(1000, 10000, 100)
df.sort_values(by='year', inplace=True)
df.reset_index(drop=True, inplace=True)
df['year_interval'] = pd.cut(df['year'], bins=range(1950, 2025, 5), labels=range(1950, 2020, 5), include_lowest=True)
df['year_interval'] = df['year_interval'].astype(str) '-' (df['year_interval'].astype(int) 4).astype(str)
df['company'] =['Walmart', 'Amazon', 'Apple', 'CVS Health', 'UnitedHealth Group', 'Exxon Mobil', 'Berkshire Hathaway', 'Alphabet', 'McKesson', 'AmerisourceBergen', 'Costco Wholesale', 'Cigna', 'AT&T', 'Microsoft', 'Cardinal Health', 'Chevron', 'Home Depot', 'Walgreens Boots Alliance', 'Marathon Petroleum', 'Elevance Health', 'Kroger', 'Ford Motor', 'Verizon Communications', 'JPMorgan Chase', 'General Motors', 'Centene', 'Meta Platforms', 'Comcast', 'Phillips 66', 'Valero Energy', 'Dell Technologies', 'Target', 'Fannie Mae', 'United Parcel Service', 'Lowe\'s', 'Bank of America', 'Johnson & Johnson', 'Archer Daniels Midland', 'FedEx', 'Humana', 'Wells Fargo', 'State Farm Insurance', 'Pfizer', 'Citigroup', 'PepsiCo', 'Intel', 'Procter & Gamble', 'General Electric', 'IBM', 'MetLife', 'Prudential Financial', 'Albertsons', 'Walt Disney', 'Energy Transfer', 'Lockheed Martin', 'Freddie Mac', 'Goldman Sachs Group', 'Raytheon Technologies', 'HP', 'Boeing', 'Morgan Stanley', 'HCA Healthcare', 'AbbVie', 'Dow', 'Tesla', 'Allstate', 'American International Group', 'Best Buy', 'Charter Communications', 'Sysco', 'Merck', 'New York Life Insurance', 'Caterpillar', 'Cisco Systems', 'TJX', 'Publix Super Markets', 'ConocoPhillips', 'Liberty Mutual Insurance Group', 'Progressive', 'Nationwide', 'Tyson Foods', 'Bristol-Myers Squibb', 'Nike', 'Deere', 'American Express', 'Abbott Laboratories', 'StoneX Group', 'Plains GP Holdings', 'Enterprise Products Partners', 'TIAA', 'Oracle', 'Thermo Fisher Scientific', 'Coca-Cola', 'General Dynamics', 'CHS', 'USAA', 'Northwestern Mutual', 'Nucor', 'Exelon', 'Massachusetts Mutual Life Insurance']
df
###
year revenue year_interval company
0 1951 8951 1950-1954 Walmart
1 1954 7270 1950-1954 Amazon
2 1955 7148 1950-1954 Apple
3 1955 5661 1950-1954 CVS Health
4 1955 5179 1950-1954 UnitedHealth Group
.. ... ... ... ...
95 2016 4945 2015-2019 USAA
96 2016 6860 2015-2019 Northwestern Mutual
97 2017 6535 2015-2019 Nucor
98 2018 6235 2015-2019 Exelon
99 2019 8624 2015-2019 Massachusetts Mutual Life Insurance
[100 rows x 4 columns]
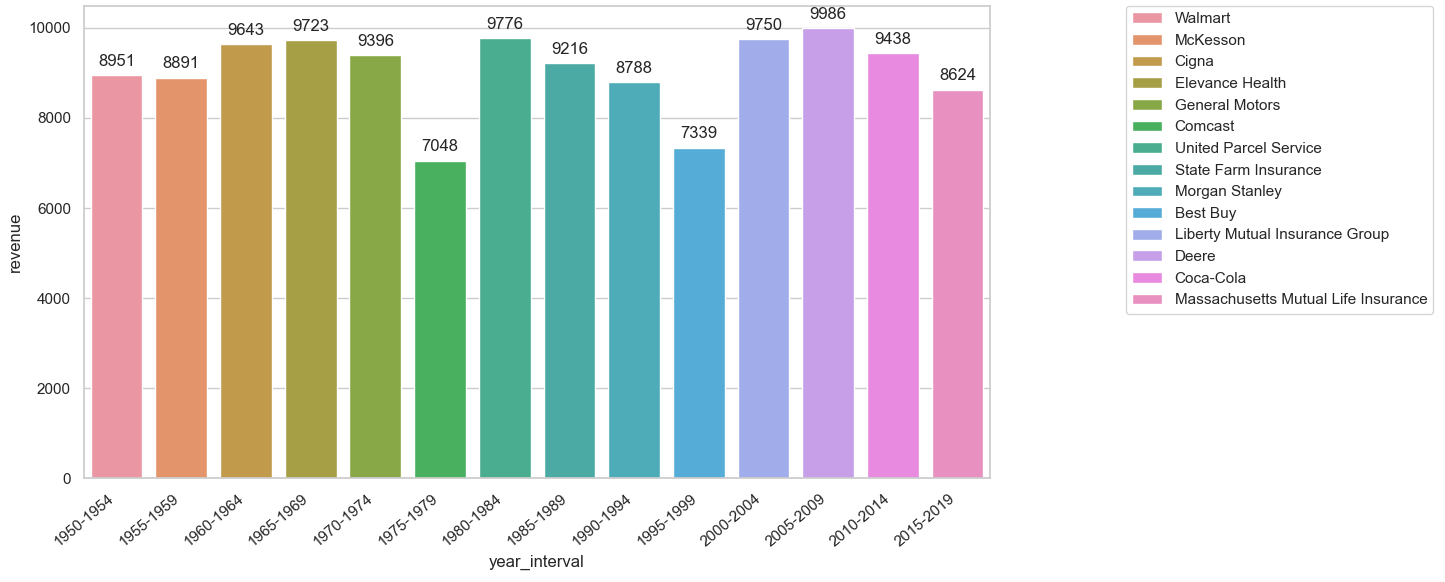
Finding company having max revenue of each year_interval
df_max = df.groupby('year_interval')['revenue'].max().reset_index()
df_result = df_max.merge(df, on=['year_interval', 'revenue'], how='left')
df_result
###
year_interval revenue year company
0 1950-1954 8951 1951 Walmart
1 1955-1959 8891 1959 McKesson
2 1960-1964 9643 1962 Cigna
3 1965-1969 9723 1970 Elevance Health
4 1970-1974 9396 1973 General Motors
5 1975-1979 7048 1978 Comcast
6 1980-1984 9776 1982 United Parcel Service
7 1985-1989 9216 1986 State Farm Insurance
8 1990-1994 8788 1994 Morgan Stanley
9 1995-1999 7339 1997 Best Buy
10 2000-2004 9750 2003 Liberty Mutual Insurance Group
11 2005-2009 9986 2008 Deere
12 2010-2014 9438 2014 Coca-Cola
13 2015-2019 8624 2019 Massachusetts Mutual Life Insurance
Plot,
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid")
plt.gcf().set_size_inches(15, 6)
ax = sns.barplot(x="year_interval", y="revenue", hue="company", data=df_result, dodge=False)
ax.set_xticklabels(ax.get_xticklabels(), rotation=40, ha="right")
plt.legend(bbox_to_anchor=(1.15, 1), loc=2, borderaxespad=0.)
for p in ax.patches:
ax.annotate(format(p.get_height(), '.0f'), (p.get_x() p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 10), textcoords = 'offset points')
plt.tight_layout()
plt.show()
CodePudding user response:
Save extrema of intervals separately
df['decade1'] = df['year'] - df['year'] % 10
df['decade2'] = df['year'] (10 - df['year'] % 10)
Also, you can save it as a string in the format you wanted
df['decade'] = df['decade1'].astype(str).str.cat(df['decade1'].values.astype(str), sep='-')
Other than this you might find ways to handle time series data in pandas of which I am unaware.