I'm stuck on this because I'm not quite sure how to ask the question, so here's my best attempt!
I have a list of tuples which represent a temperature reading at a particular timestamp.
[
(datetime.datetime(2022, 11, 30, 8, 25, 10, 261853), 19.82),
(datetime.datetime(2022, 11, 30, 8, 27, 22, 479093), 20.01),
(datetime.datetime(2022, 11, 30, 8, 27, 36, 984757), 19.96),
(datetime.datetime(2022, 11, 30, 8, 36, 46, 651432), 21.25),
(datetime.datetime(2022, 11, 30, 8, 41, 27, 230438), 21.42),
...
(datetime.datetime(2022, 11, 30, 11, 57, 4, 689363), 17.8)
]
As you can see, the deltas between the records are all over the place - some are a few seconds apart, while others are minutes apart.
From these, I want to create a new list of tuples (or other data structure - I am happy to use NumPy or Pandas) where the timestamp value is exactly every 5 minutes, while the temperature reading is calculated as the assumed value at that timestamp given the data that is available. Something like this:
[
(datetime.datetime(2022, 11, 30, 8, 25, 0, 0), ??),
(datetime.datetime(2022, 11, 30, 8, 30, 0, 0), ??),
(datetime.datetime(2022, 11, 30, 8, 35, 0, 0), ??),
(datetime.datetime(2022, 11, 30, 8, 40, 0, 0), ??),
...
(datetime.datetime(2022, 11, 30, 11, 30, 0, 0), ??),
]
My end goal is to be able to plot this data using PIL, but not MatPlotLib as I'm on very constrained hardware. I want to plot a smooth temperature line over a given time period, given the imperfect data I have on hand.
CodePudding user response:
Assuming lst the input list, you can use:
import pandas as pd
out = (
pd.DataFrame(lst).set_index(0).resample('5min')
.mean().interpolate('linear')
.reset_index().to_numpy().tolist()
)
If you really want a list of tuples:
out = list(map(tuple, out))
Output:
[[Timestamp('2022-11-30 08:25:00'), 19.930000000000003],
[Timestamp('2022-11-30 08:30:00'), 20.590000000000003],
[Timestamp('2022-11-30 08:35:00'), 21.25],
[Timestamp('2022-11-30 08:40:00'), 21.42],
[Timestamp('2022-11-30 08:45:00'), 21.32717948717949],
[Timestamp('2022-11-30 08:50:00'), 21.234358974358976],
...
[Timestamp('2022-11-30 11:45:00'), 17.985641025641026],
[Timestamp('2022-11-30 11:50:00'), 17.892820512820514],
[Timestamp('2022-11-30 11:55:00'), 17.8]]
For datetime types:
out = (
pd.DataFrame(lst).set_index(0).resample('5min')
.mean().interpolate('linear')[1]
)
out = list(zip(out.index.to_pydatetime(), out))
Output:
[(datetime.datetime(2022, 11, 30, 8, 25), 19.930000000000003),
(datetime.datetime(2022, 11, 30, 8, 30), 20.590000000000003),
(datetime.datetime(2022, 11, 30, 8, 35), 21.25),
(datetime.datetime(2022, 11, 30, 8, 40), 21.42),
(datetime.datetime(2022, 11, 30, 8, 45), 21.32717948717949),
(datetime.datetime(2022, 11, 30, 8, 50), 21.234358974358976),
...
(datetime.datetime(2022, 11, 30, 11, 45), 17.985641025641026),
(datetime.datetime(2022, 11, 30, 11, 50), 17.892820512820514),
(datetime.datetime(2022, 11, 30, 11, 55), 17.8)]
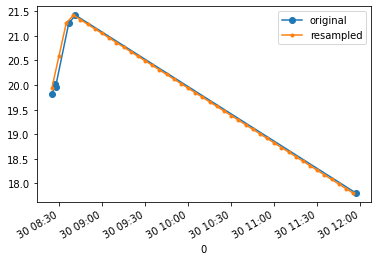
Before/after resampling: