i have a df as follows:
df = pd.DataFrame.from_dict({'Type': {0: 'A1', 1: 'A2', 2: 'A2', 3: 'A2', 4: 'A2', 5: 'A3', 6: 'A3', 7: 'A3', 8: 'A3', 9: 'A3', 10: 'A3', 11: 'A3', 12: 'A3', 13: 'A3', 14: 'A3', 15: 'A3', 16: 'A3', 17: 'A3', 18: 'A3', 19: 'A3', 20: 'A3', 21: 'A3', 22: 'A3', 23: 'A3', 24: 'A3', 25: 'A3', 26: 'A3', 27: 'A3', 28: 'A3', 29: 'A3', 30: 'A3', 31: 'A3', 32: 'A3', 33: 'A3', 34: 'A3', 35: 'A3', 36: 'A3', 37: 'A3', 38: 'A3', 39: 'A3', 40: 'A3', 41: 'A3', 42: 'A3', 43: 'A3', 44: 'A3', 45: 'A3', 46: 'A3', 47: 'A3', 48: 'A3', 49: 'A3', 50: 'A3', 51: 'A3', 52: 'A3', 53: 'A3', 54: 'A3', 55: 'A3', 56: 'A3', 57: 'A3', 58: 'A3', 59: 'A3', 60: 'A3', 61: 'A3', 62: 'A3', 63: 'A3', 64: 'A3', 65: 'A3', 66: 'A3', 67: 'A3', 68: 'A3', 69: 'A3', 70: 'A3', 71: 'A3', 72: 'A3', 73: 'A3', 74: 'A3', 75: 'A3'}, 'FN': {0: 'F1', 1: 'F2', 2: 'F3', 3: 'F3', 4: 'F4', 5: 'F5', 6: 'F5', 7: 'F5', 8: 'F6', 9: 'F6', 10: 'F6', 11: 'F6', 12: 'F7', 13: 'F7', 14: 'F1', 15: 'F1', 16: 'F8', 17: 'F8', 18: 'F8', 19: 'F8', 20: 'F8', 21: 'F9', 22: 'F9', 23: 'F9', 24: 'F10', 25: 'F10', 26: 'F11', 27: 'F12', 28: 'F12', 29: 'F13', 30: 'F13', 31: 'F14', 32: 'F14', 33: 'F15', 34: 'F15', 35: 'F16', 36: 'F16', 37: 'F16', 38: 'F17', 39: 'F17', 40: 'F18', 41: 'F3', 42: 'F3', 43: 'F3', 44: 'F3', 45: 'F19', 46: 'F20', 47: 'F21', 48: 'F22', 49: 'F23', 50: 'F23', 51: 'F24', 52: 'F25', 53: 'F26', 54: 'F26', 55: 'F27', 56: 'F27', 57: 'F27', 58: 'F28', 59: 'F29', 60: 'F30', 61: 'F30', 62: 'F31', 63: 'F31', 64: 'F32', 65: 'F32', 66: 'F33', 67: 'F34', 68: 'F34', 69: 'F35', 70: 'F35', 71: 'F36', 72: 'F37', 73: 'F37', 74: 'F38', 75: 'F39'}, 'ID': {0: 'S1', 1: 'S2', 2: 'S3', 3: 'S4', 4: 'S5', 5: 'S6', 6: 'S6', 7: 'S7', 8: 'S8', 9: 'S9', 10: 'S10', 11: 'S11', 12: 'S12', 13: 'S13', 14: 'S1', 15: 'S1', 16: 'S14', 17: 'S15', 18: 'S16', 19: 'S17', 20: 'S17', 21: 'S18', 22: 'S18', 23: 'S19', 24: 'S20', 25: 'S21', 26: 'S22', 27: 'S23', 28: 'S23', 29: 'S24', 30: 'S25', 31: 'S26', 32: 'S27', 33: 'S28', 34: 'S28', 35: 'S29', 36: 'S29', 37: 'S29', 38: 'S30', 39: 'S30', 40: 'S31', 41: 'S32', 42: 'S32', 43: 'S3', 44: 'S3', 45: 'S33', 46: 'S34', 47: 'S35', 48: 'S36', 49: 'S37', 50: 'S38', 51: 'S39', 52: 'S40', 53: 'S41', 54: 'S41', 55: 'S42', 56: 'S43', 57: 'S44', 58: 'S45', 59: 'S46', 60: 'S47', 61: 'S48', 62: 'S49', 63: 'S49', 64: 'S50', 65: 'S50', 66: 'S51', 67: 'S52', 68: 'S52', 69: 'S53', 70: 'S53', 71: 'S54', 72: 'S55', 73: 'S55', 74: 'S56', 75: 'S57'}, 'DN': {0: 'D1', 1: 'D2', 2: 'D3', 3: 'D4', 4: 'D5', 5: 'D6', 6: 'D6', 7: 'D7', 8: 'D8', 9: 'D9', 10: 'D10', 11: 'D11', 12: 'D12', 13: 'D13', 14: 'D1', 15: 'D1', 16: 'D14', 17: 'D15', 18: 'D16', 19: 'D17', 20: 'D17', 21: 'D18', 22: 'D18', 23: 'D19', 24: 'D20', 25: 'D21', 26: 'D22', 27: 'D23', 28: 'D23', 29: 'D24', 30: 'D25', 31: 'D26', 32: 'D27', 33: 'D28', 34: 'D28', 35: 'D29', 36: 'D29', 37: 'D29', 38: 'D30', 39: 'D30', 40: 'D31', 41: 'D32', 42: 'D32', 43: 'D3', 44: 'D3', 45: 'D33', 46: 'D34', 47: 'D35', 48: 'D36', 49: 'D37', 50: 'D38', 51: 'D39', 52: 'D40', 53: 'D41', 54: 'D41', 55: 'D42', 56: 'D43', 57: 'D44', 58: 'D45', 59: 'D46', 60: 'D47', 61: 'D48', 62: 'D49', 63: 'D49', 64: 'D50', 65: 'D50', 66: 'D51', 67: 'D52', 68: 'D52', 69: 'D53', 70: 'D53', 71: 'D54', 72: 'D55', 73: 'D55', 74: 'D56', 75: 'D57'}, 'Group': {0: 'FC', 1: 'SCZ', 2: 'FC', 3: 'SCZ', 4: 'SCZ', 5: 'FC', 6: 'FC', 7: 'FC', 8: 'FC', 9: 'FC', 10: 'FC', 11: 'FC', 12: 'FC', 13: 'FC', 14: 'FC', 15: 'FC', 16: 'BPAD', 17: 'BPAD', 18: 'FC', 19: 'FC', 20: 'FC', 21: 'FC', 22: 'FC', 23: 'FC', 24: 'BPAD', 25: 'SCZ', 26: 'FC', 27: 'PC', 28: 'PC', 29: 'FC', 30: 'FC', 31: 'FC', 32: 'FC', 33: 'FC', 34: 'FC', 35: 'FC', 36: 'FC', 37: 'FC', 38: 'FC', 39: 'FC', 40: 'FC', 41: 'FC', 42: 'FC', 43: 'FC', 44: 'FC', 45: 'FC', 46: 'FC', 47: 'FC', 48: 'FC', 49: 'FC', 50: 'FC', 51: 'FC', 52: 'FC', 53: 'FC', 54: 'FC', 55: 'FC', 56: 'FC', 57: 'SCZ', 58: 'FC', 59: 'FC', 60: 'FC', 61: 'SCZ', 62: 'PC', 63: 'PC', 64: 'PC', 65: 'PC', 66: 'PC', 67: 'PC', 68: 'PC', 69: 'PC', 70: 'PC', 71: 'PC', 72: 'PC', 73: 'PC', 74: 'PC', 75: 'PC'}, 'POS': {0: 'C1', 1: 'C2', 2: 'C3', 3: 'C3', 4: 'C4', 5: 'C5', 6: 'C6', 7: 'C7', 8: 'C5', 9: 'C5', 10: 'C5', 11: 'C5', 12: 'C5', 13: 'C5', 14: 'C8', 15: 'C7', 16: 'C9', 17: 'C7', 18: 'C5', 19: 'C5', 20: 'C6', 21: 'C5', 22: 'C7', 23: 'C5', 24: 'C7', 25: 'C7', 26: 'C5', 27: 'C5', 28: 'C10', 29: 'C11', 30: 'C5', 31: 'C5', 32: 'C5', 33: 'C5', 34: 'C7', 35: 'C12', 36: 'C5', 37: 'C7', 38: 'C5', 39: 'C7', 40: 'C5', 41: 'C13', 42: 'C5', 43: 'C13', 44: 'C5', 45: 'C5', 46: 'C5', 47: 'C5', 48: 'C5', 49: 'C5', 50: 'C5', 51: 'C5', 52: 'C5', 53: 'C5', 54: 'C14', 55: 'C5', 56: 'C5', 57: 'C5', 58: 'C5', 59: 'C5', 60: 'C5', 61: 'C5', 62: 'C5', 63: 'C7', 64: 'C5', 65: 'C7', 66: 'C5', 67: 'C5', 68: 'C7', 69: 'C5', 70: 'C7', 71: 'C5', 72: 'C5', 73: 'C7', 74: 'C5', 75: 'C15'}, 'VC': {0: 'MI', 1: 'MI', 2: 'IN', 3: 'IN', 4: 'MI', 5: 'MI', 6: 'LOF', 7: 'MI', 8: 'MI', 9: 'MI', 10: 'MI', 11: 'MI', 12: 'MI', 13: 'MI', 14: 'MI', 15: 'MI', 16: 'MI', 17: 'MI', 18: 'MI', 19: 'MI', 20: 'LOF', 21: 'MI', 22: 'MI', 23: 'MI', 24: 'MI', 25: 'MI', 26: 'MI', 27: 'MI', 28: 'MI', 29: 'MI', 30: 'MI', 31: 'MI', 32: 'MI', 33: 'MI', 34: 'MI', 35: 'MI', 36: 'MI', 37: 'MI', 38: 'MI', 39: 'MI', 40: 'MI', 41: 'MI', 42: 'MI', 43: 'MI', 44: 'MI', 45: 'MI', 46: 'MI', 47: 'MI', 48: 'MI', 49: 'MI', 50: 'MI', 51: 'MI', 52: 'MI', 53: 'MI', 54: 'MI', 55: 'MI', 56: 'MI', 57: 'MI', 58: 'MI', 59: 'MI', 60: 'MI', 61: 'MI', 62: 'MI', 63: 'MI', 64: 'MI', 65: 'MI', 66: 'MI', 67: 'MI', 68: 'MI', 69: 'MI', 70: 'MI', 71: 'MI', 72: 'MI', 73: 'MI', 74: 'MI', 75: 'MI'}})
I wanted to expand and shrink columns simulataneously such that the output look as follws:
Type POS FN VC ID DN FC SCZ BPAD PC
A1 C1 F1 MI S1 D1 1 0 0 0
A2 C2 F2 MI S2 D2 0 1 0 0
C3 F3 IN S3|S4 D3|D4 1 1 0 0
C4 F4 MI S5 D5 0 1 0 0
A3 C5 F5 MI S6 D6 1 0 0 0
F6 MI S8|S9|S10|S11 D8|D9|D10|D11 3 0 0 1
F7 MI S12|S13 D11|D12 2 0 0 0
C6 F5 LOF S6 D6 1 0 0 0
C7 F1 MI S1 D1 1 0 0 0
F5 MI S7 D7 1 0 0 0
F8 MI S15 D15 0 0 1 0
C8 F1 MI S1 D1 1 0 0 0
F8 MI S14 D14 0 0 1 0
I tried the following code to shrink and expand the data
df1 = df.groupby(['Type', 'FN']).agg(lambda x: '|'.join(x.unique()))[['POS', 'VC', 'ID', 'DN']]
df2 = pd.get_dummies(df.set_index(['Type', 'FN'])['Group']).sum(level=[0, 1])
pd.concat([df1, df2], axis=1)
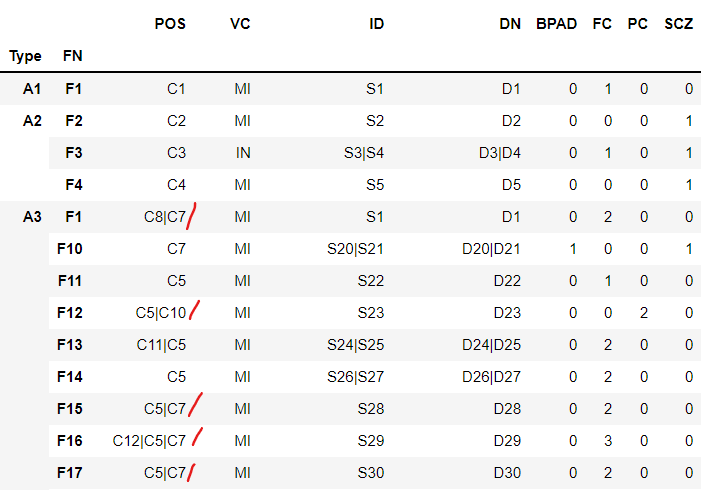
But in the output POS also got splitted, but I wanted to expand that
CodePudding user response:
I think you need aggregate per 3 columns:
df1 = df.groupby(['Type','POS', 'FN'])[['VC','ID','DN']].agg(lambda x: '|'.join(x.unique()))
df2 = pd.get_dummies(df.set_index(['Type','POS', 'FN'])['Group']).sum(level=[0, 1, 2])
df = pd.concat([df1, df2], axis=1)
print (df.head(20))
VC ID DN BPAD FC PC SCZ
Type POS FN
A1 C1 F1 MI S1 D1 0 1 0 0
A2 C2 F2 MI S2 D2 0 0 0 1
C3 F3 IN S3|S4 D3|D4 0 1 0 1
C4 F4 MI S5 D5 0 0 0 1
A3 C10 F12 MI S23 D23 0 0 1 0
C11 F13 MI S24 D24 0 1 0 0
C12 F16 MI S29 D29 0 1 0 0
C13 F3 MI S32|S3 D32|D3 0 2 0 0
C14 F26 MI S41 D41 0 1 0 0
C15 F39 MI S57 D57 0 0 1 0
C5 F11 MI S22 D22 0 1 0 0
F12 MI S23 D23 0 0 1 0
F13 MI S25 D25 0 1 0 0
F14 MI S26|S27 D26|D27 0 2 0 0
F15 MI S28 D28 0 1 0 0
F16 MI S29 D29 0 1 0 0
F17 MI S30 D30 0 1 0 0
F18 MI S31 D31 0 1 0 0
F19 MI S33 D33 0 1 0 0
F20 MI S34 D34 0 1 0 0