When computing A @ a where A is a random N by N matrix and a is a vector with N random elements using numpy the computation time jumps by an order of magnitude at N=100. Is there any particular reason for this? As a comparison the same operation using torch on the cpu has a more gradual increase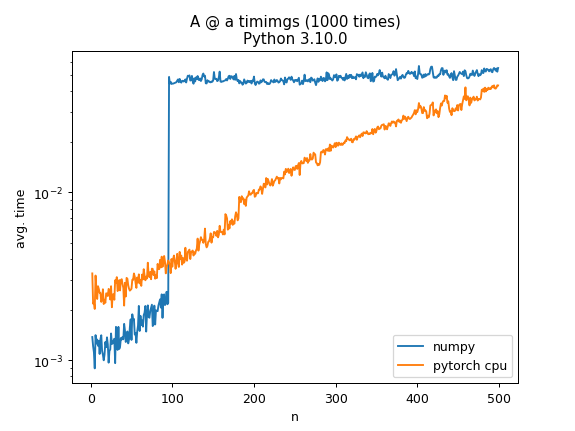
Tried it with python3.10 and 3.9 and 3.7 with the same behavior
Code used for generating numpy part of the plot:
import numpy as np
from tqdm.notebook import tqdm
import pandas as pd
import time
import sys
def sym(A):
return .5 * (A A.T)
results = []
for n in tqdm(range(2, 500)):
for trial_idx in range(10):
A = sym(np.random.randn(n, n))
a = np.random.randn(n)
t = time.time()
for i in range(1000):
A @ a
t = time.time() - t
results.append({
'n': n,
'time': t,
'method': 'numpy',
})
results = pd.DataFrame(results)
from matplotlib import pyplot as plt
fig, ax = plt.subplots(1, 1)
ax.semilogy(results.n.unique(), results.groupby('n').time.mean(), label="numpy")
ax.set_title(f'A @ a timimgs (1000 times)\nPython {sys.version.split(" ")[0]}')
ax.legend()
ax.set_xlabel('n')
ax.set_ylabel('avg. time')
Update
Adding
import os
os.environ["MKL_NUM_THREADS"] = "1"
os.environ["NUMEXPR_NUM_THREADS"] = "1"
os.environ["OMP_NUM_THREADS"] = "1"
before ìmport numpy gives a more expected output, see this answer for details: 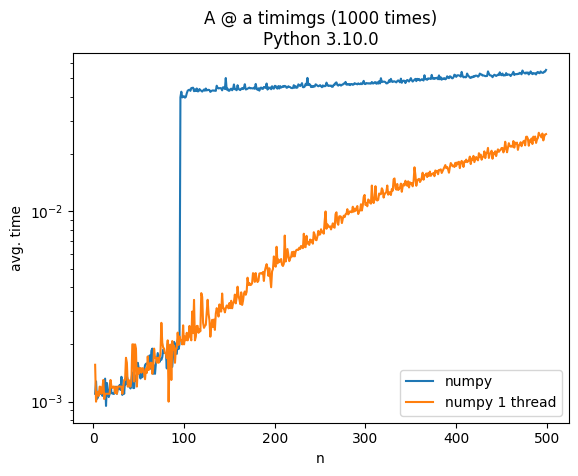
CodePudding user response:
numpy tries to use threads when multiplying matricies of size 100 or larger, and the default CBLAS implementation of threaded multiplication is ... sub optimal, as opposed to other backends like intel-MKL or ATLAS.
if you force it to use only 1 thread using the answers in this post you will get a continuous line for numpy performance.