I have a data frame that looks like this.
import pandas as pd
import numpy as np
data = [
['A',1,2,3,4],
['A',5,6,7,8],
['A',9,10,11,12],
['B',13,14,15,16],
['B',17,18,19,20],
['B',21,22,23,24],
['B',25,26,27,28],
['C',29,30,31,32],
['C',33,34,35,36],
['C',37,38,39,40],
['D',13,14,15,0],
['D',0,18,19,0],
['D',0,0,23,0],
['D',0,0,0,0],
['E',13,14,15,0],
['E',0,18,19,0],
['F',0,0,23,0],
]
df = pd.DataFrame(data, columns=['Name', 'num1', 'num2', 'num3', 'num4'])
df
Then I have the following code to calculate the group by weighted average.
weights = [10,20,30,40]
df=df.groupby('Name').agg(lambda g: sum(g*weights[:len(g)])/sum(weights[:len(g)]))
The problem lies in sum(weights[:len(g)]) because all the groups do not have equal rows. As you can see above, group A has 3 rows, B has 4 rows, C has 3 rows, D has 4 rows, E has 2 rows and F has 1 row.
Depending upon the rows, it needs to calculate the sum.
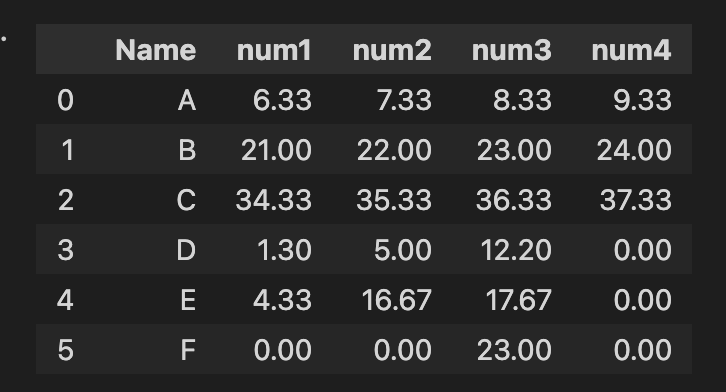
Now, the above code returns me the weighted average by calculating
For Group A, the first column calculates the weighted average as (1 X 10 5 X 20 9 X 30)/60 but it should calculate the weighted average as (1 X20 5 X 30 9 X 40)/90
For Group E, the first column calculates the weighted average as (13 X 10 0 X 20)/30 but it should calculate the weighted average as (13 X 30 0 X 40)/70
Current Result
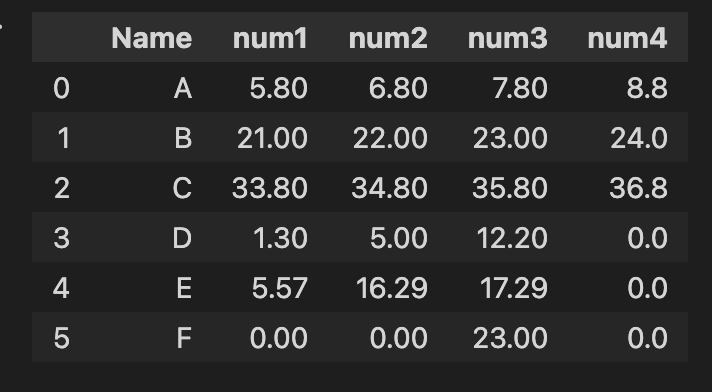
Expected result
CodePudding user response:
i edit your code little bit
n = len(weights)
df=df.groupby('Name').agg(lambda g: sum(g*weights[n-len(g):])/sum(weights[n-len(g):]))
output(df):
num1 num2 num3 num4
Name
A 5.9 6.9 7.9 8.9
B 21.0 22.0 23.0 24.0
C 33.9 34.9 35.9 36.9
D 1.3 5.0 12.2 0.0
E 5.6 16.3 17.3 0.0
F 0.0 0.0 23.0 0.0
CodePudding user response:
@PandaKim's solution suffices; for efficiency, depending on your data size, you may have to take a longer route:
n = len(weights)
pos = n - df.groupby('Name').size()
pos = [weights[posn : n] for posn in pos]
pos = np.concatenate(pos)
(df
.set_index('Name')
.mul(pos, axis=0)
.assign(wt = pos)
.groupby('Name')
.sum()
.pipe(lambda df: df.filter(like='num')
.div(df.wt, axis=0)
)
)
num1 num2 num3 num4
Name
A 5.888889 6.888889 7.888889 8.888889
B 21.000000 22.000000 23.000000 24.000000
C 33.888889 34.888889 35.888889 36.888889
D 1.300000 5.000000 12.200000 0.000000
E 5.571429 16.285714 17.285714 0.000000
F 0.000000 0.000000 23.000000 0.000000