Trying to understand the optimal way to loop over data in python that isn't formatted as a table (tr/td)
Example Data:
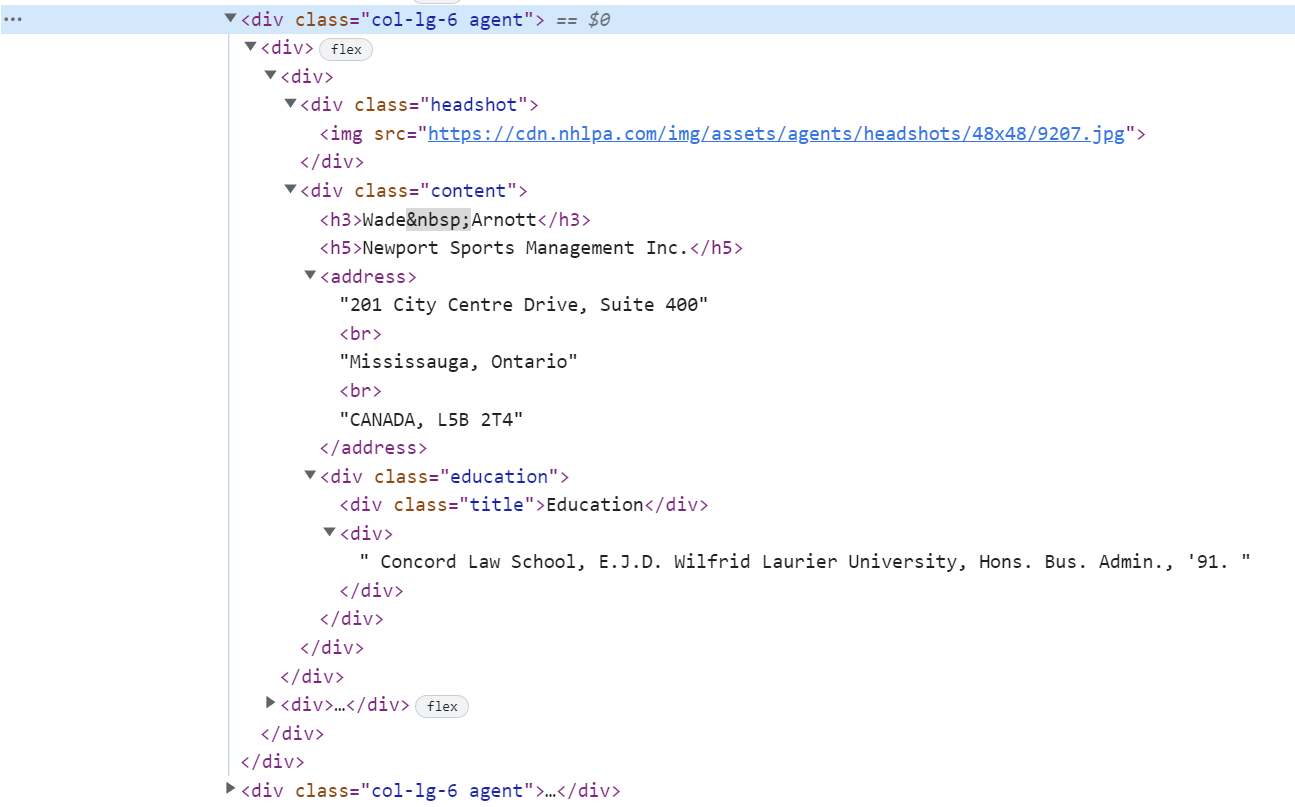
Trying to create a table for Name, headshot URL, Company, Address, Education.
Trying to following so far but cannot seem to understand how to go into the divs for the content component:
r=requests.get(url)
soup=BeautifulSoup(r.text, 'html5lib')
table = soup.find_all('div', attrs = {'class':'col-lg-6 agent'})
for a in table:
if a.find('div', attrs = {'headshot'}):
headshot_url=a.find('div', attrs = {'headshot'}).img```
CodePudding user response:
Simply iterate all the agents and pick your specific information to store them in a list of dicts:
for e in soup.select('.agent'):
data.append({
'name':e.h3.get_text(strip=True).replace('\xa0',' '),
'headshot_url':e.img.get('src'),
'company':e.h5.get_text(strip=True),
'address':e.address.get_text(strip=True) if e.address else None,
'education':e.select_one('.education div div').get_text(strip=True)
})
This could be transformed into a dataframe.
Example
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://www.nhlpa.com/the-pa/certified-agents?range=A-Z'
r = requests.get(url)
soup = BeautifulSoup(r.text)
data = []
for e in soup.select('.agent'):
data.append({
'name':e.h3.get_text(strip=True).replace('\xa0',' '),
'headshot_url':e.img.get('src'),
'company':e.h5.get_text(strip=True),
'address':e.address.get_text(strip=True) if e.address else None,
'education':e.select_one('.education div div').get_text(strip=True)
})
pd.DataFrame(data)
Output
| name | headshot_url | company | address | education | |
|---|---|---|---|---|---|
| 0 | Wade Arnott | https://cdn.nhlpa.com/img/assets/agents/headshots/48x48/9207.jpg | Newport Sports Management Inc. | 201 City Centre Drive, Suite 400Mississauga, OntarioCANADA, L5B 2T4 | Concord Law School, E.J.D. |
| Wilfrid Laurier University, Hons. Bus. Admin., '91. | |||||
| 1 | Patrik Aronsson | https://cdn.nhlpa.com/img/assets/agents/headshots/48x48/56469.jpg | AC Hockey | Faktorvagen 17 RKungsbackaSweden, 43437 | Not available. |
| 2 | Shumi Babaev | https://cdn.nhlpa.com/img/assets/agents/headshots/48x48/56794.jpg | Shumi Babaev Agency | Moscow Mining University (Moscow) 1989-1994 - Masters' Degree | |
| 3 | Mika Backman | https://cdn.nhlpa.com/img/assets/agents/headshots/48x48/58054.jpg | WSG Finland Ltd. | Kappelikuja 6 C02200 EspooFinland, | Helsinki University Law School (1992-1998) - Master of Law |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
...
CodePudding user response:
Hope this helps <3
r=requests.get(url)
print("fetched")
soup=BeautifulSoup(r.text, 'html.parser')
table = soup.find_all('div', attrs = {'class':'col-lg-6 agent'})
for a in table:
headshots=a.find('div', attrs = {'headshot'})
#find all divs with headshot class
if headshots:
#check if not None
headshot_url=headshots.img["src"]
#get the url
else:
headshot_url=None
#So nothing gets wrong with our data sets
content=a.find('div', attrs = {'content'})
#find all divs with content class
if content:
#check if the div actually exist
if content.h3:
name=str(content.h3.contents[0]).replace("\xa0"," ")
else:
name=None
if content.h5:
company=content.h5.contents[0]
else:
company=None
else:
name,company=None,None
#if content is None, then by default both of these None
html_address=content.address
if html_address:
address=html_address.contents[0]
#You might wanna edit this if you want
else:
address=None
edu=a.find("div",attrs={'education'}).find("div",attrs={"class":None})
#find all divs with education class
if edu:
education=edu.contents[0]
else:
education=None
#YOUR FINAL DATA SET IS:
data_set={"headshot_url":headshot_url,"name":name,"company":company,'address':address,'education':education}