I have a dataset in the following form:
timestamp consumption
2017-01-01 00:00:00 14.3
2017-01-01 01:00:00 29.1
2017-01-01 02:00:00 28.7
2017-01-01 03:00:00 21.3
2017-01-01 04:00:00 18.4
... ... ...
2017-12-31 19:00:00 53.2
2017-12-31 20:00:00 43.5
2017-12-31 21:00:00 37.1
2017-12-31 22:00:00 35.8
2017-12-31 23:00:00 33.8
And I want to perform anomaly detection in the sense that it predicts abnormal high or low values.
I am performing isolation forest:
IF = IsolationForest(random_state=0, contamination=0.005, n_estimators=200, max_samples=0.7)
IF.fit(model_data)
# New Outliers Column
data['Outliers'] = pd.Series(IF.predict(model_data)).apply(lambda x: 1 if x == -1 else 0)
# Get Anomaly Score
score = IF.decision_function(model_data)
# New Anomaly Score column
data['Score'] = score
data.head()
The result that I am getting as outliers is the following:
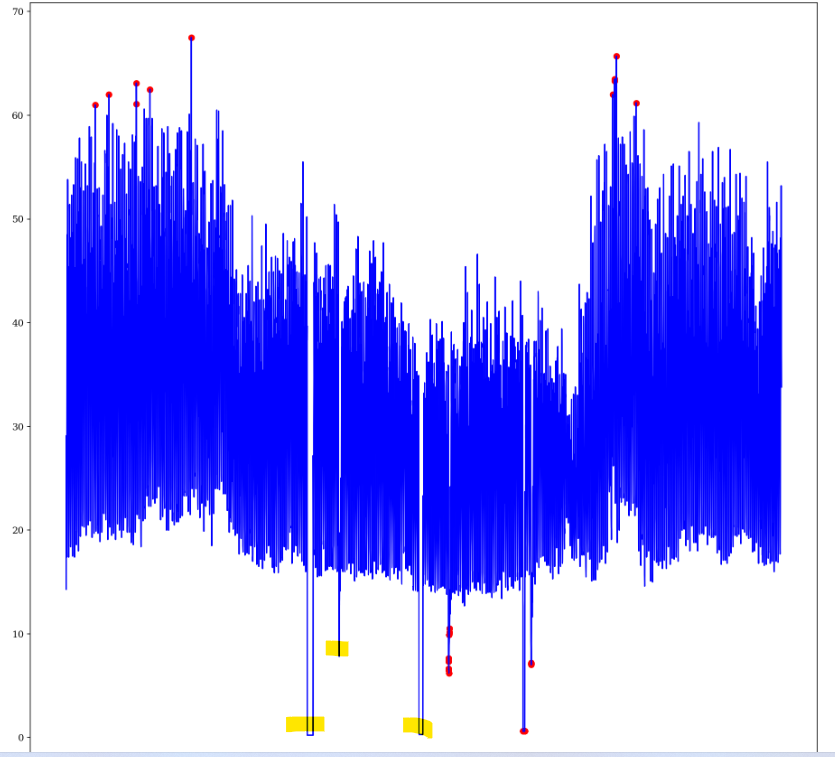
It seems that identifies the peaks, but it misses some low values that are apparently outliers and I have highlighted them in the plot.
Any idea of what is causing this error?
CodePudding user response:
The values highlighted in yellow seems to repeat themselves. So the model encountered these values several times, and won't consider them as outliers. As you're training and testing your model on the same dataset, this is not very surprising, the model is overfitting. Using a forest based algorithm for a univariate timeseries seems overkill to me. I'll start with a simple algorithm computing a rolling mean and the standard deviation to find outliers before using anything more complex.