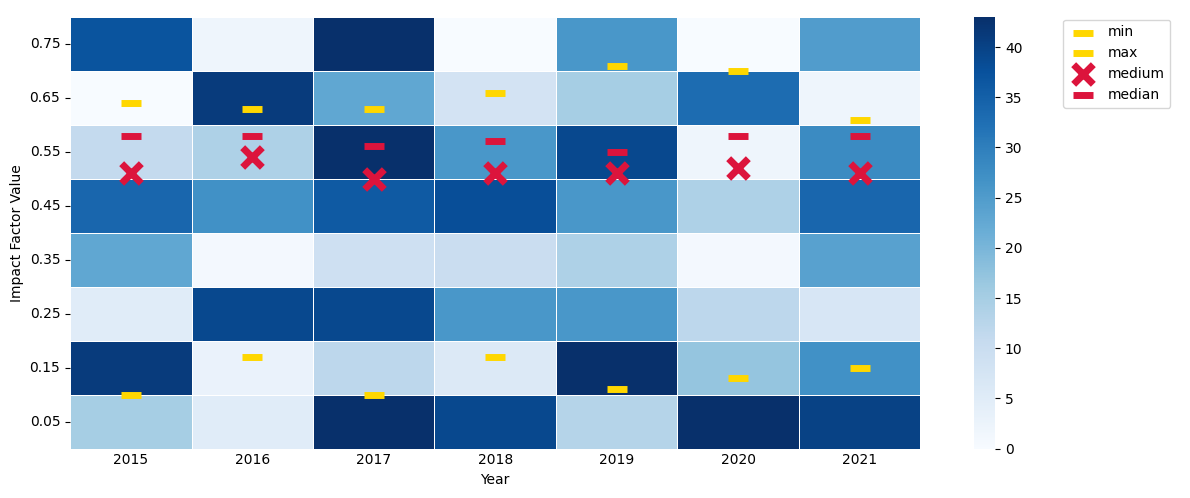
I would like to add to a heatmap the min, max, medium and median values of the same data that is the foundation for the heatmap. Is there a possible way to do this without post-processing of the figure in Illustrator/...?
My code so far is:
# import of libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# create dataframe
df_dynEFs = pd.DataFrame()
# read data and write into dataframe
df_dynEFs = pd.read_csv('dynEFs_data.csv')
df_dynEFs.head()
# pivot long table into wide table
df_dynEFs = df_dynEFs.pivot("Impact Factor Value", "Year", "Value")
# draw heatmap
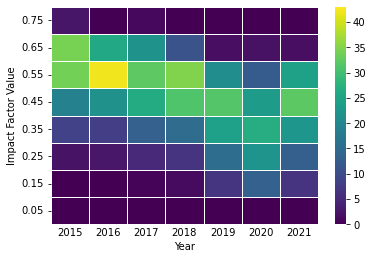
fig, ax = plt.subplots()
ax = sns.heatmap(df_dynEFs, annot=False, linewidth=.5, cmap="viridis", vmin=0, vmax=43, ax=ax)
ax.invert_yaxis()
plt.yticks(rotation=0)
ax.tick_params(axis=u'x', which=u'both',length=0)
Which yields the following figure:
Now I would like to add further data, namely min, max, medium and median values. Some sample data for that additional information could be the following:
Year,min,max,medium,median
2015,0.15,0.7,0.53,0.56
2016,0.15,0.7,0.53,0.56
2017,0.15,0.7,0.53,0.56
2018,0.15,0.7,0.53,0.56
2019,0.15,0.7,0.53,0.56
2020,0.15,0.7,0.53,0.56
2021,0.15,0.7,0.53,0.56
The y-axis on the left should be visually the same for the heatmap as well as the additional information of the data (though, this could also achieved by using an auxilliary y-axis on the right and afterwards hide this axis?). I imagine it something like this:
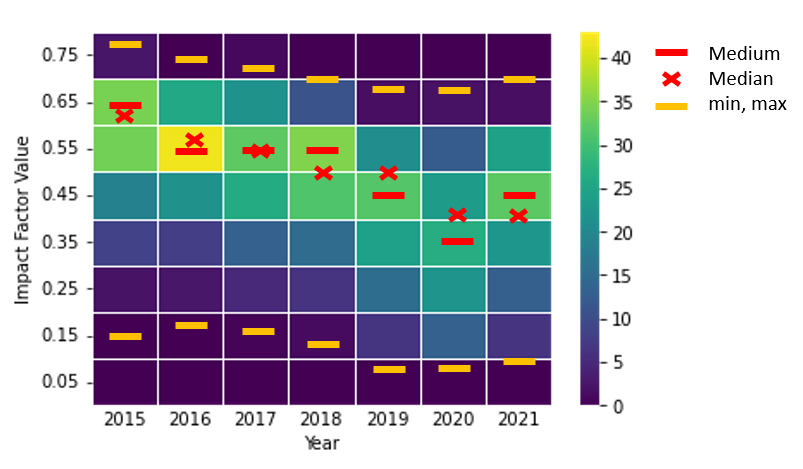
Does anyone have an idea how to obtain this in Python? Thanks in advance!
CodePudding user response:
You can use np.interp(values, tick_values, tick_label_values) to convert the numeric values to their position given the categorical ticks.
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
factors = np.arange(5, 80, 10) / 100
years = np.arange(2015, 2022)
df_dynEFs_long = pd.DataFrame({"Impact Factor Value": np.repeat(factors, len(years)),
"Year": np.tile(years, len(factors)),
"Value": np.random.randint(0, 50, len(years) * len(factors))})
df_dynEFs = df_dynEFs_long.pivot(index="Impact Factor Value", columns="Year", values="Value")
df_stats = pd.DataFrame({'Year': years,
'min': np.random.randint(10, 20, len(years)) / 100,
'max': np.random.randint(60, 80, len(years)) / 100,
'medium': np.random.randint(50, 55, len(years)) / 100,
'median': np.random.randint(55, 60, len(years)) / 100})
fig, ax = plt.subplots(figsize=(12, 5))
sns.heatmap(df_dynEFs, annot=False, linewidth=.5, cmap="Blues", vmin=0, vmax=43, ax=ax)
ax.invert_yaxis()
ax.tick_params(axis='x', which='both', length=0)
ax.tick_params(rotation=0)
year_ticks = ax.get_xticks()
factor_ticks = ax.get_yticks()
for column in df_stats.columns[1:]:
ax.scatter(x=year_ticks,
y=np.interp(df_stats[column], factors, factor_ticks),
marker='x' if column == 'medium' else '_', s=200, lw=5,
color='gold' if column in ['min', 'max'] else 'crimson',
label=column)
ax.legend(loc='upper left', bbox_to_anchor=(1.16, 1.01))
plt.tight_layout()
plt.show()