I have sample data in SQL Server below:
drop table if exists #test;
create table #test (id char(4), product char(1), inception date, salary int, grp_start bit, grp_end bit);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2003-03-01', 125000,1,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2004-03-01', 150000,0,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2005-03-01', 300000,0,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2006-03-01', 400000,0,1);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'L', '2016-03-01', 500000,1,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'L', '2016-10-01', 450000,0,1);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2018-10-01', 130000,1,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2020-03-01', 150000,0,1);
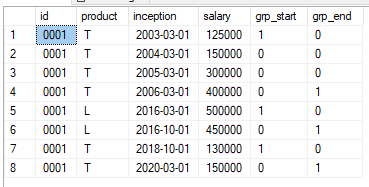
I'd like to group this data based on grp_start and grp_end and run an aggregate function over it like min()
I'm probably overcomplicating this, but I'd like to find a way to create a dynamic window that would encapsulate rows 1-4, rows 5-6 and rows 7-8 and take the minimum salary in the group. The window groups are marked appropriately.
My intuition wanted to try a min(salary) over (partition by product, id order by inception) or a rolling sum total that essentially aggregates these "groups" up until the value in each group is = 2. grp_start grp_end = 2 for each group (1 for the grp_start and 1 for the grp_end). I'm just not sure how to go about doing it.
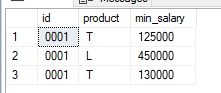
Desired result:
CodePudding user response:
You're on the right track with adding group start and end, but I think ranking the salaries within the group and selecting the row with the lowest rank is the best way to implement it.
create table #test (id char(4), product char(1), inception date, salary int, grp_start bit, grp_end bit);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2003-03-01', 125000,1,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2004-03-01', 150000,0,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2005-03-01', 300000,0,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2006-03-01', 400000,0,1);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'L', '2016-03-01', 500000,1,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'L', '2016-10-01', 450000,0,1);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2018-10-01', 130000,1,0);
insert into #test (id, product, inception, salary, grp_start, grp_end) values('0001', 'T', '2020-03-01', 150000,0,1);
with ctePre as (
SELECT *
, SUM(CONVERT(INT, grp_start) CONVERT(INT,grp_end))
OVER (PARTITION BY id ORDER BY inception
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as Grp
FROM #test
), cteGrouped as (
SELECT id, product, inception, salary, grp_start, grp_end
, grp, floor((Grp 1) /2) as grpFinal
FROM ctePre as P
), cteSorted as (
SELECT *, ROW_NUMBER() OVER (PARTITION BY id, grpFinal ORDER BY Salary) as SalRank
FROM cteGrouped as G
)
SELECT id, product, inception, salary
FROM cteSorted as S
WHERE SalRank = 1
drop table #test;
gives results
| id | product | inception | salary |
|---|---|---|---|
| 0001 | T | 2003-03-01 | 125000 |
| 0001 | L | 2016-10-01 | 450000 |
| 0001 | T | 2018-10-01 | 130000 |