I have output file that can be read by a visualizing tool, the problem is that at the beginning of each line there is one space. Because of this the visualizing tool isn't able to recognize the scripts and, hence crashing. When I manually remove the first column of spaces, it works fine. Is there a way to remove the 1st empty column of spaces using bash command 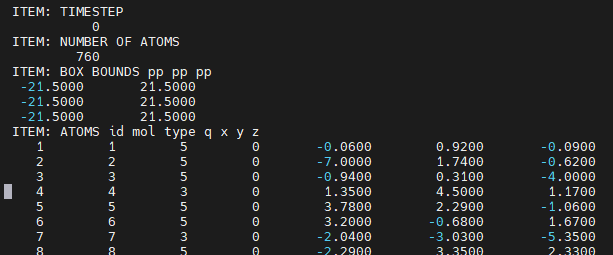
What I want is to remove the excess column of empty space like shown in this second image using a bash command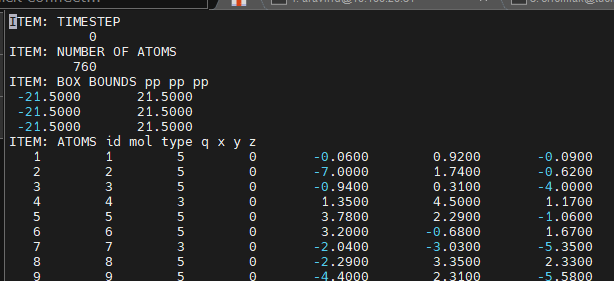
At present I use Vim editor to remove the 1st column manually. But I would like to do it using a bash command so that I can automate the process. My file is not just full of columns, it has some independent data line
CodePudding user response:
Using cut or sed would be two simple solutions.
cut
cut -c2- file > file.cut && mv file.cut file
cut cannot modify a file, therefore you need to redirect its output to a different file and then overwrite the old file with the new file.
sed
sed -i 's/^.//' file
-i modifies the file in-place.
CodePudding user response:
I would use
sed -ie 's/^ //' file
to just remove spaces (in case a line does not contain it)