first of all, in case I comment on any mistakes while writing this, sorry, English is not my first language.
So I started to study data science and data visualization in sports with Python just for hobby, I'm a really begginer on this. I want to calculate the percentile of each columns based on the highest value, I will put a image below, for example, in the column ''xg'', the highest value is 1.03, I want to transform this value in a new column with the value 100%. And so on in the other columns

I want to do something like this:
[The stat/the percentile of stat compared to all rows]
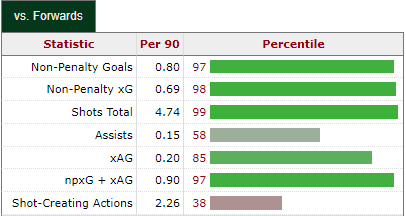 I
I
CodePudding user response:
You can simply calculate percentile values based on the highest value of each column like this:
import pandas as pd
df = pd.DataFrame({
'ID': [1, 2, 3, 4, 5, 6, 7],
'xg': [0.25, 0.77, 1.03, 0.12, 0.66, 0.79, 0.92],
'passes': [15, 19, 22, 26, 23, 12, 31],
'pass_completion': [80, 73, 66, 74, 92, 50, 70],
'progression': [7, 5, 12, 5, 8, 4, 14],
})
"""
ID xg passes pass_completion progression
0 1 0.25 15 80 7
1 2 0.77 19 73 5
2 3 1.03 22 66 12
3 4 0.12 26 74 5
4 5 0.66 23 92 8
5 6 0.79 12 50 4
6 7 0.92 31 70 14
"""
# Following code is what you want to do
df['xg_percentile'] = df['xg']/max(df['xg'])
df['passes_percentile'] = df['passes']/max(df['passes'])
df['pass_completion_percentile'] = df['pass_completion']/max(df['pass_completion'])
df['progression_percentile'] = df['progression']/max(df['progression'])
print(df)
ID xg passes pass_completion progression xg_percentile passes_percentile pass_completion_percentile progression_percentile
0 1 0.25 15 80 7 0.242718 0.483871 0.869565 0.500000
1 2 0.77 19 73 5 0.747573 0.612903 0.793478 0.357143
2 3 1.03 22 66 12 1.000000 0.709677 0.717391 0.857143
3 4 0.12 26 74 5 0.116505 0.838710 0.804348 0.357143
4 5 0.66 23 92 8 0.640777 0.741935 1.000000 0.571429
5 6 0.79 12 50 4 0.766990 0.387097 0.543478 0.285714
6 7 0.92 31 70 14 0.893204 1.000000 0.760870 1.000000
CodePudding user response:
you can use pandas.DataFrame.rank function pandas.DataFrame.rank
import pandas as pd
data_dict = {
"xg":[0.25,0.77,1.03,0.12,0.66,0.79,0.92],
"passes":[15,19,22,26,23,12,31],
"passCompletion":[80,72,66,74,92,50,70],
"progression":[7,5,12,5,8,4,14]}
df = pd.DataFrame(data_dict)
df['xg_pctile'] = df.xg.rank(pct = True)