I am trying to create a pandas dataframe with selenium objects 'left' and 'right'.
left = driver.find_elements(by=By.CLASS_NAME, value='lc')
right = driver.find_elements(by=By.CLASS_NAME, value='rc')
These return strings as ojects which has a different number of values for each item in left and right. But left and right has same number of elements for an iteration. The strings from 'left' are column names and values from 'right' has to be appended to the corresponding column names. I tried the following:
for l, r in zip(left, right):
# Get the text from the left and right elements
l_text = l.text
r_text = r.text
# Create a dictionary for the row with the left text as the key and the right text as the value
row = {l_text: r_text}
# Append the dictionary to the list
data.append(row)
# Create the dataframe from the list of dictionaries
df = pd.DataFrame(data)
The df created out of it has a problem with the index such that each value is added to a new index instead of being added to the same row. How do I add all values from an iteration to the same row.
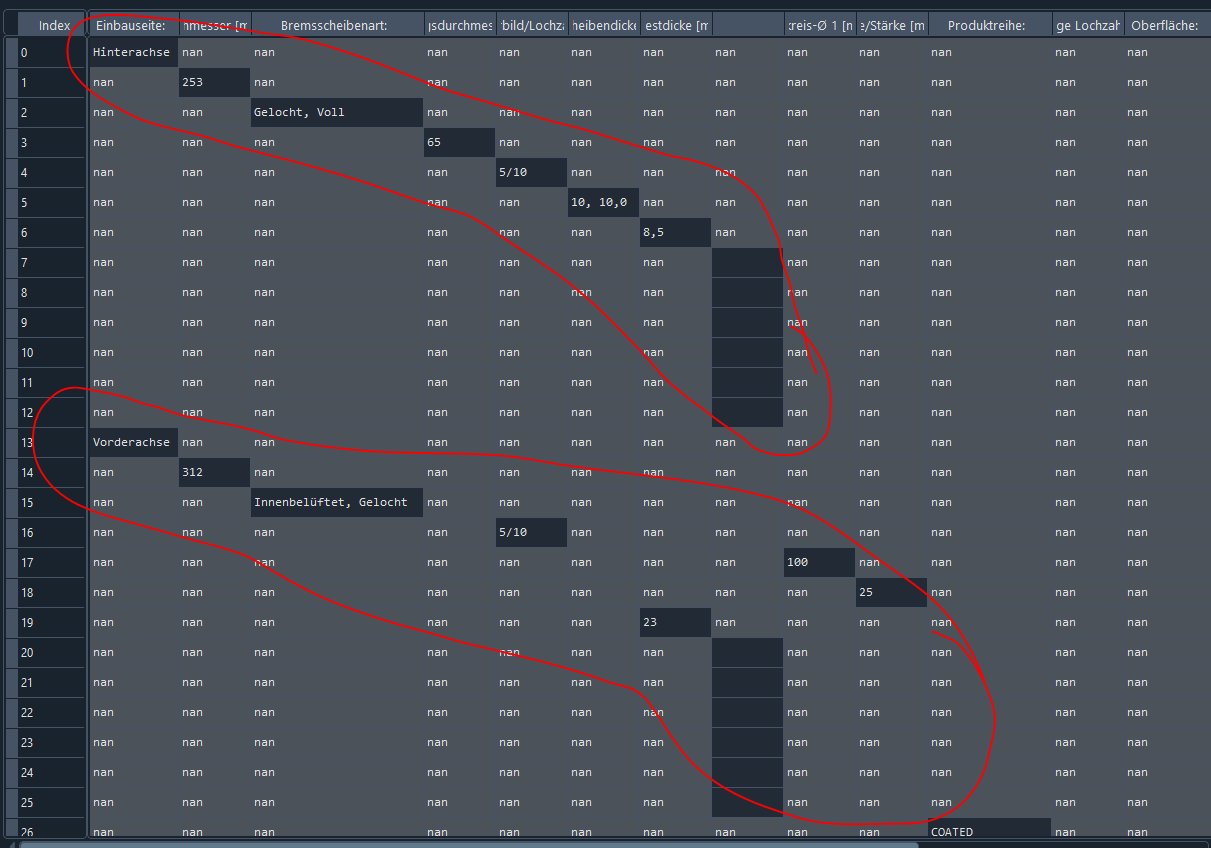
The 'left' values are attributes of brake disks and the 'right' refers to its corresponding values. These vary for each item sometimes there are more and sometimes less.

CodePudding user response:
I made some adjustments to your code when I append each key, value in a dictionary then append it to the dataframe
data = pd.DataFrame()
dic = {}
for l, r in zip(left, right):
# Get the text from the left and right elements
dic[l.text] = r.text
# Create a dictionary for the row with the left text as the key and the right text as the value
# Append the dictionary to the list
data = data.append(dic,ignore_index=True)
#data is your final dataframe
CodePudding user response:
Try do it this way:
left = driver.find_elements(by=By.CLASS_NAME, value='lc')
right = driver.find_elements(by=By.CLASS_NAME, value='rc')
# Create a dictionary with keys from the left and empty lists as values
data = {}
for element in left:
if element.text not in data.keys():
data[element.text] = list()
for l, r in zip(left, right):
# Add an element to list by key
data[l.text].append(r.text)
# Create the dataframe from the dictionary
df = pd.DataFrame.from_dict(data)
I have not worked with selenium so you may need to tweak the code a little (in terms of getting a text from left list values).
CodePudding user response:
The following should do what you want:
- Items are added to the row until it encounters the same header.
- Once a duplicate header is discovered, the
rowvariable is appended todataand then cleared for the next round / row.
left = driver.find_elements(by=By.CLASS_NAME, value='lc')
right = driver.find_elements(by=By.CLASS_NAME, value='rc')
data=[]
row={}
for l, r in zip(left, right):
# Get the text from the left and right elements
l_text = l.text
r_text = r.text
if l_text in row:
data.append(row)
row = {}
else:
row[l_text] = r_text
# This is required to append the last row
if len(row) > 0:
data.append(row)
# Create the dataframe from the list of dictionaries
df = pd.DataFrame(data)
print(df)