My string is a comment that looks like:
***z|Samuel|Amount:15|Frequency:1
I want to use regex to filter all such rows out of a data base, my query is below
select
ID,
COMMENT,
max(case when lower(COMMENT) Rlike '\* z\|Samuel\|Amount:[0-9] \|Frequency:[0-9] '
then 1 else 0 end) as indicator
from Table_Name group by 1,2
But this gives me an error:
Invalid regular expression: '* z|Samuel|Amount:[0-9] |Frequency:[0-9] ', no argument for repetition operator: *
Does anyone know how to navigate through this?
CodePudding user response:
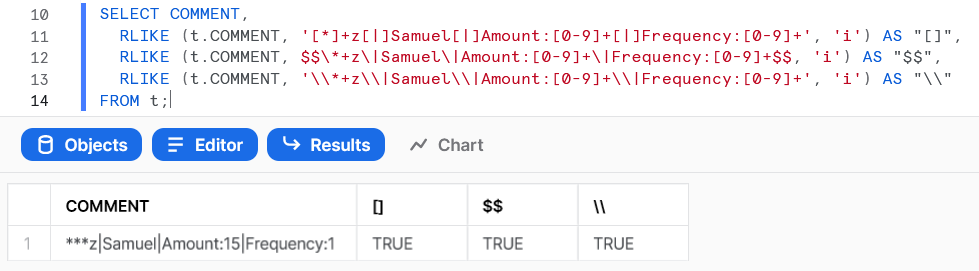
Using '[*] z[|]Samuel[|]Amount:[0-9] [|]Frequency:[0-9] ':
CREATE OR REPLACE TEMPORARY TABLE t AS
SELECT '***z|Samuel|Amount:15|Frequency:1' AS COMMENT;
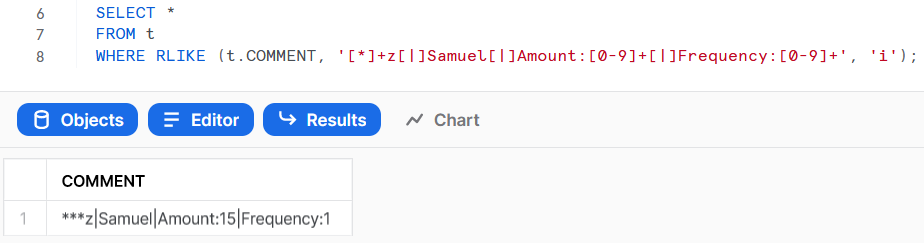
SELECT *
FROM t
WHERE RLIKE (t.COMMENT, '[*] z[|]Samuel[|]Amount:[0-9] [|]Frequency:[0-9] ', 'i');
Output:
Alternatively the original \ should be doubled or the string not wrapped with ':
'\* z\|Samuel\|Amount:[0-9] \|Frequency:[0-9] '
=>
'\\* z\\|Samuel\\|Amount:[0-9] \\|Frequency:[0-9] '
$$\* z\|Samuel\|Amount:[0-9] \|Frequency:[0-9] $$